Releasing Hosted Evaluations: Making benchmarking effortless

Releasing Hosted Evaluations: Making benchmarking effortless
Today, we are releasing Hosted Evaluations, giving everyone access to scalable infrastructure to test models on their own evaluations.
Evaluations are the cornerstone of LLM research and the subsequent deployment of the models. They make us able to figure out what the model can, and, more importantly, can't do. Without them, we'd be stuck with vibes, single prompt tests and cherry-picked examples from model vendors. Evaluations give us insights into the strengths (and weaknesses) of different models in a range of domains and capabilities.
Evaluations evolved over time
The set of capabilities we care about has changed a lot over the years. Consequently, the benchmarks have evolved, guiding the development of the next generation of models.
In the early phases of LLM research, we mostly cared about knowledge-based benchmarks such as MMLU-Pro to assess whether a model has picked up facts from across the internet texts it was trained on. These benchmarks were graded as multiple choice, which makes them easy to evaluate.
Evaluating these benchmarks is relatively simple: You take the question from the task set, give it to the model, and then score the model's answer with a regular expression (or any other grading function) to obtain the final score.

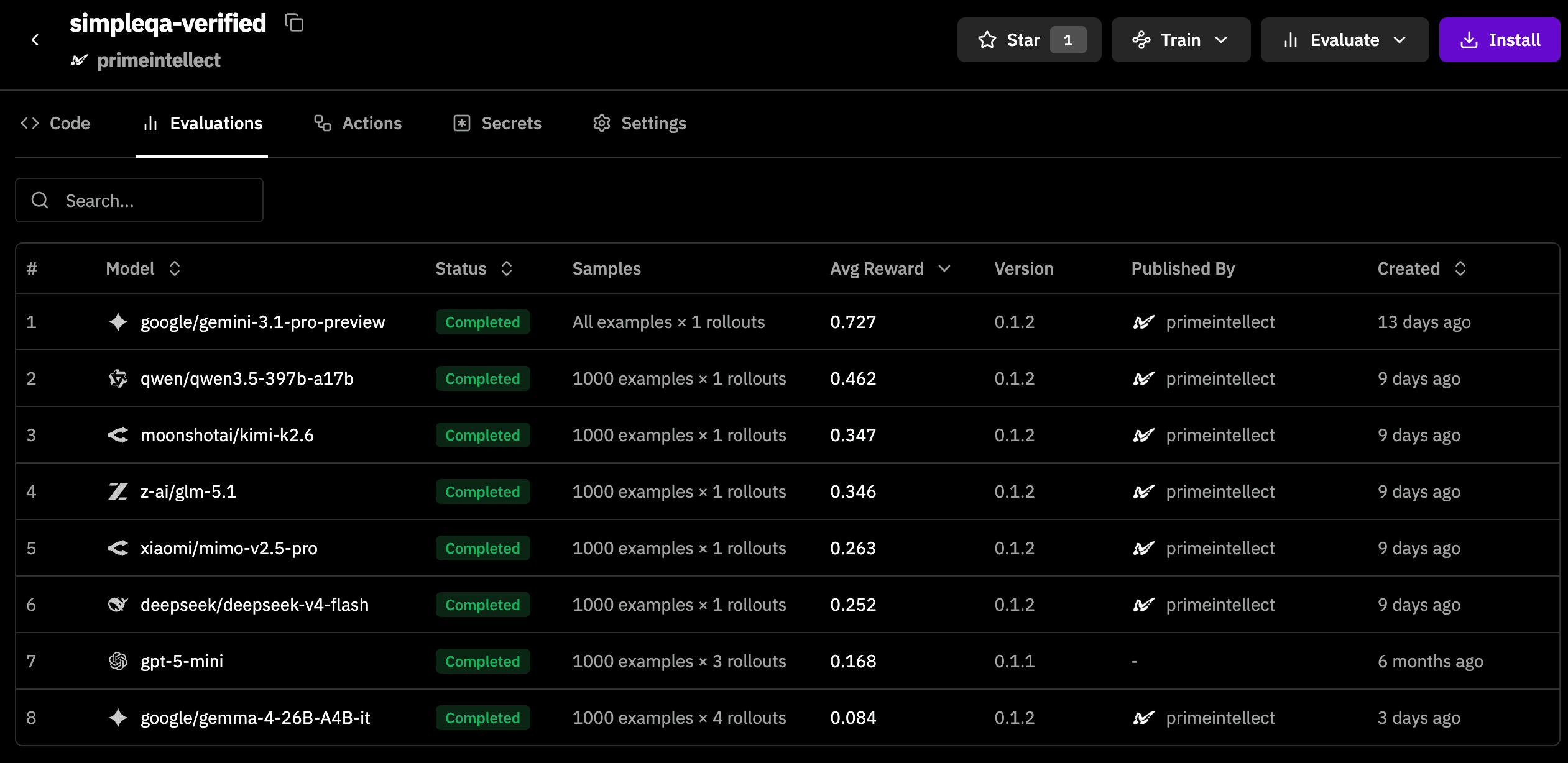
Benchmarks like SimpleQA (and its verified version with cleaned tasks) were a natural extension of these knowledge‑based tests, as the models need to string multiple facts together to answer a question. Benchmarks like these are evaluated using a second model, referred to as judge, which reads the free-form output from the first model and is asked to grade it using a rubric with the correct solution.
The strengths of different models on a given environment can be seen on the respective leaderboard:
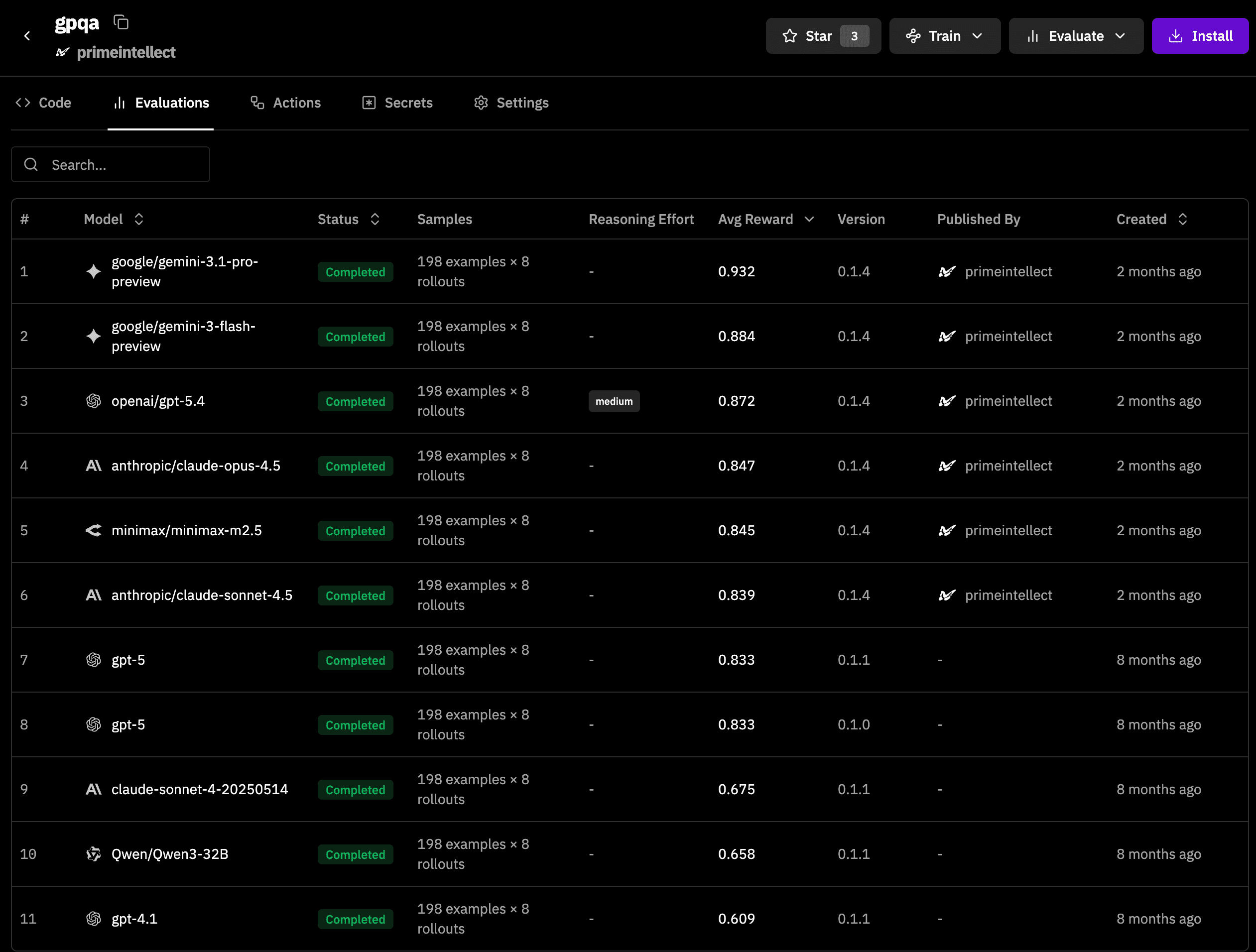
The rise of reasoning models has resulted in an increased need to evaluate models on scientific questions. One of the earliest benchmarks, GPQA Diamond, requires models to reason about biology, physics and chemistry on the level of graduate students. Math benchmarks such as AIME or APEX-shortlist are table stakes for these models, while HLE and FrontierScience are broader. All these benchmarks have one question and then require the model to reason about the problem for a long time to arrive at the final answer.
As LLMs evolved, they were increasingly put inside products. However, knowledge or reasoning evaluations weren't the right fit for specific needs, which is the reason the community has created narrow evaluations to test singular capabilities, such as IFEval for instruction following, tau3-bench for tool calling or GraphWalks for long context abilities. Meanwhile, companies like Zapier build specific evaluations like AutomationBench on the Environments Hub to reflect their business needs and use cases.
Agents pushed the capabilities even further. Benches like SWE-bench Pro, FrontierSWE or Terminalbench 2 require the model to work on a diverse set of problems for hours and try to mimic the reality of software engineering. These benchmarks work by using the model inside a harness, such as Claude Code, and placing the combination of both in an environment, such as a coding repository, requiring it to solve a specific task. These solutions were then executed after the model submitted its answer to check whether it is correct.
Evaluations are becoming infrastructure challenges
The shift from knowledge-based single prompt tasks to multi-turn agentic coding tasks also increased the requirements on the infrastructure: While single-prompt evaluations required the model to run on a single machine, modern evaluations require a lot of moving parts: Models in harnesses are running for hours on a single task, editing and running code in sandboxes. To evaluate efficiently, hundreds of sandboxes are spun up in parallel.
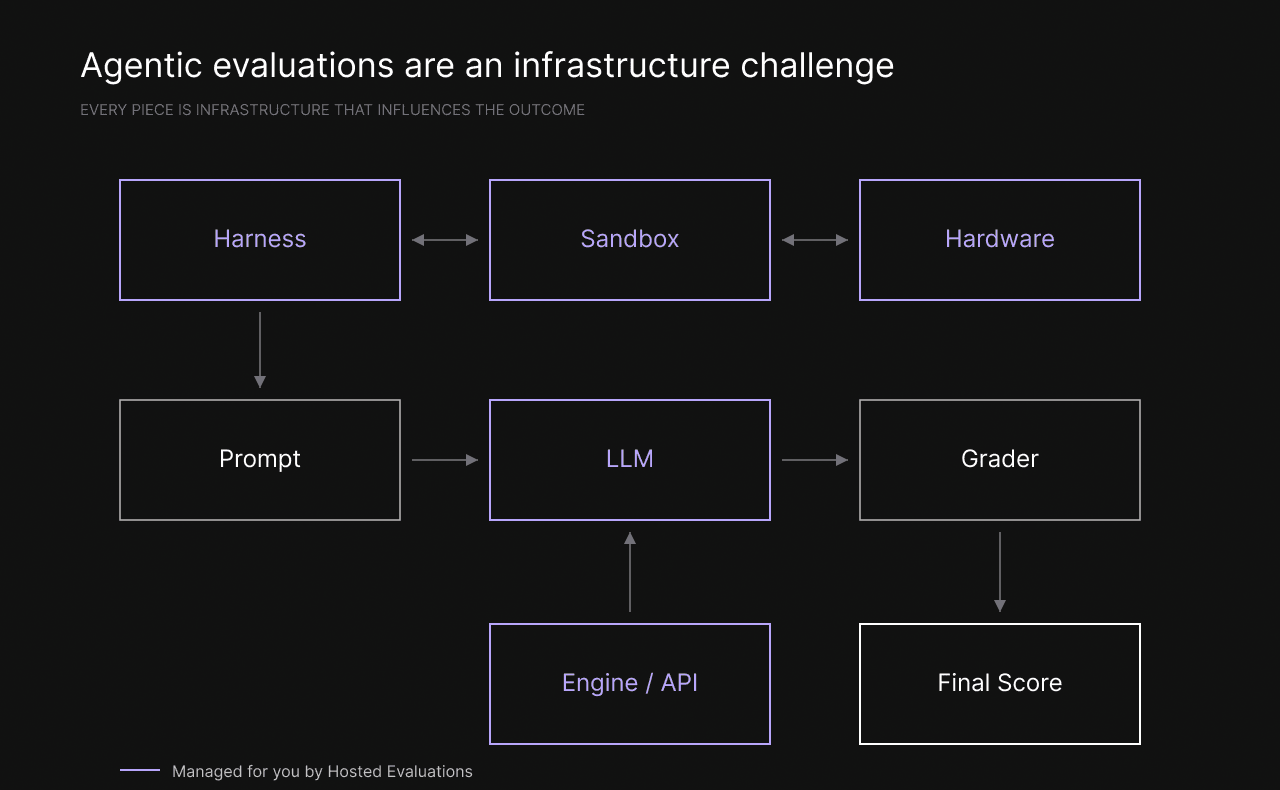
These infrastructure requirements are often overlooked, but become a huge bottleneck in research. The Prime Intellect stack is uniquely suited to fill this gap: Due to our experience with our hosted training offering Lab, we found solutions to all these challenges and can leverage them for evaluations.
To make it easy for everyone to evaluate models, we support hosted evaluations, which can be used to run evaluations on the hundreds of community-made environments already supported on the Environments Hub. Launching an evaluation is possible directly on the platform:
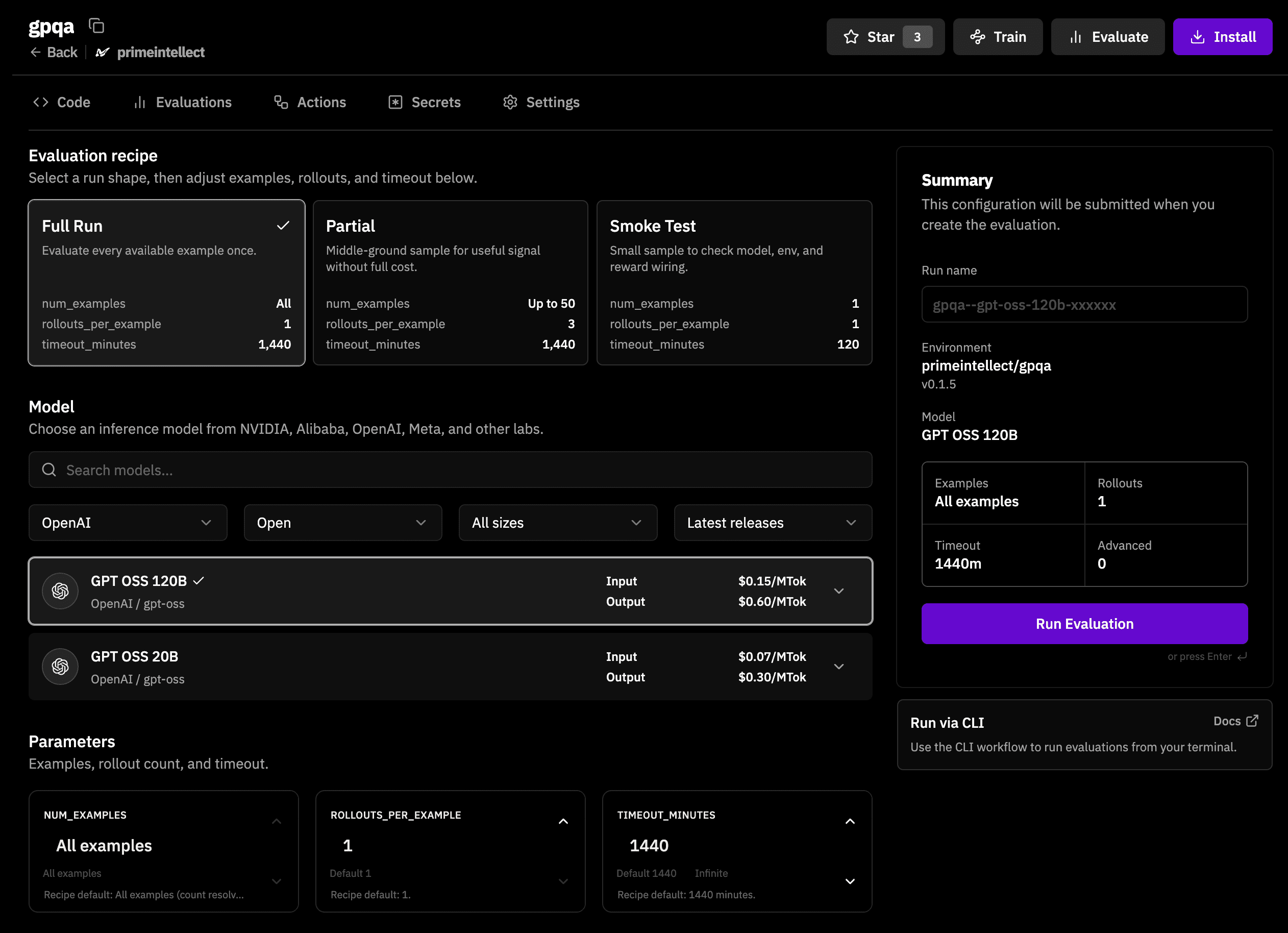
Or by using our CLI by simply appending the --hosted parameter:
prime eval run primeintellect/gpqa --model openai/gpt-oss-120b --hosted
Alternatively, you can create a .toml and similarly run it with the --hosted parameter:
[[eval]]
env_id = "primeintellect/gpqa"
model = "openai/gpt-oss-120b"
Any run evaluations for a given environment can be published on the respective leaderboard for said environment. Not only does this make it easy for anyone to quickly compare the performance of different models; it also is important for reproducibility: Because the environments are open source, every model is evaluated on the same setup.
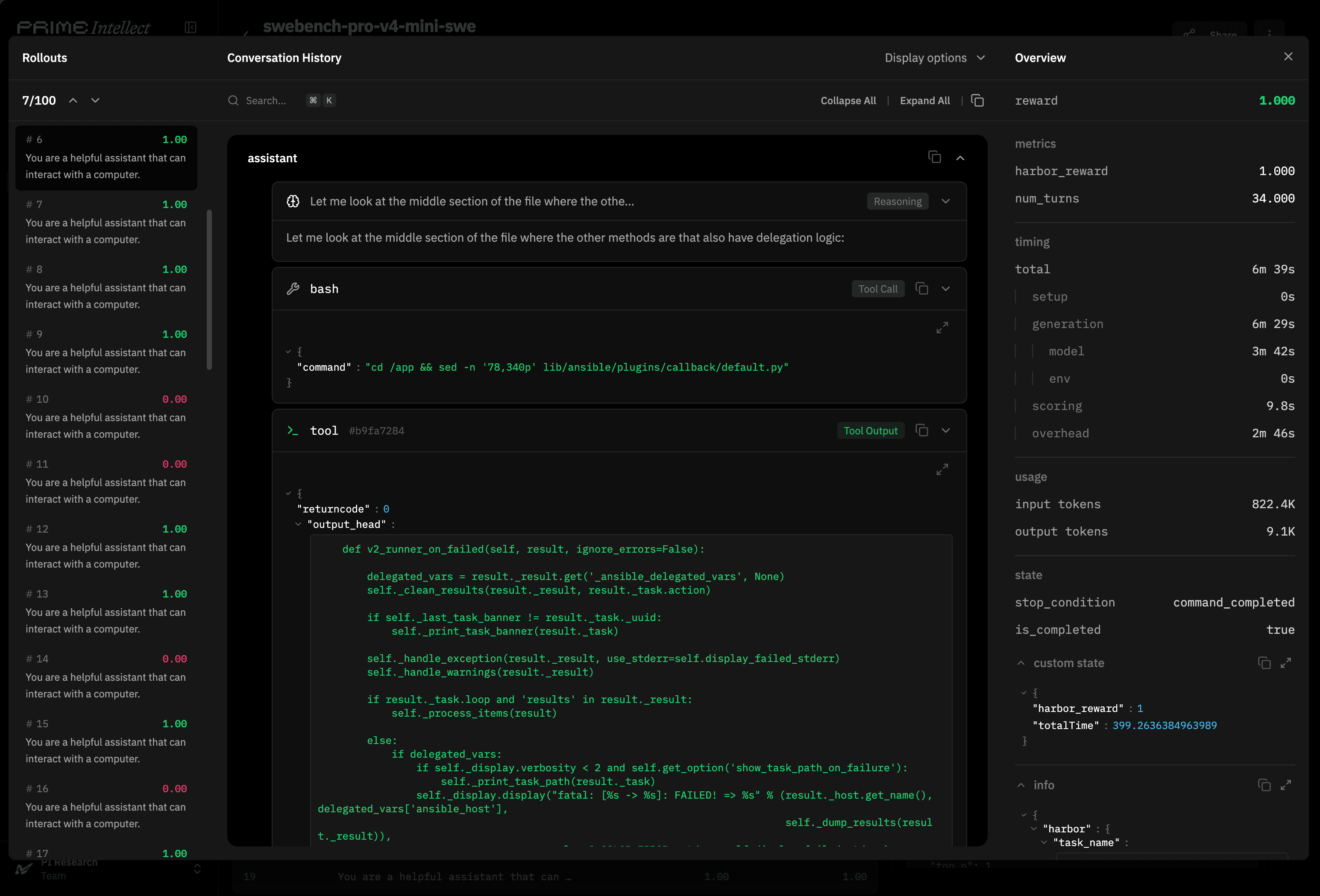
Another important aspect of the evaluations hosted on the Environments Hub is the evaluation viewer. It displays the used sampling parameters and any other settings for any evaluation run, making the results behind any number transparent for everyone.
The evaluation viewer also makes it easy to dive into the actual data by showing all the samples, as well as the respective traces, tool calls and results.
Future Directions
As evaluations become more agentic, we are making it easier to evaluate different combinations of models and harnesses for a given evaluation. For this, we are working on Verifiers v1, our open-source library powering all the environments, to provide a seamless experience.
While the Environments Hub is already one of the biggest platforms for evaluations, we are always interested in new and exciting evaluations. Reach out to us, no matter whether you are a business like Ramp or Zapier and want to leverage the infrastructure of hosted evaluations; an academic researcher who wants to broaden the audience for your evaluation; or are interested in becoming an RL resident to build new evaluations!