Releasing Lab: the training platform for self-improving agents

Releasing Lab: the training platform for self-improving agents
Today, Lab is out of beta and generally available to everyone.
Lab is our training platform for self-improving agents. It brings the full loop for agentic model improvement into one place: specify tasks, define a harness, evaluate models, train on reward signals, inspect rollouts, deploy adapters, and run inference.
You bring the task. Lab handles the training stack.
The platform includes:
- Hosted Training
- Hosted Evaluations
- Environments Hub
- Adapter Deployments
- Prime Inference
- Prime Sandboxes
We launched Lab in beta earlier this year on one premise: every AI company should be able to own its model-to-product optimization loop. Since then, hundreds of researchers, startups, and frontier teams have run more than 10,000 training jobs on the platform — math, code, browsers, games, customer support, long-horizon agents, and a handful of enterprise workflows we hadn't seen before. They built environments we hadn't thought of, and trained models we wouldn't have known how to spec.
Today, it's going live.
Environments Are the Unit of Improvement
Lab is built around environments. An environment packages everything required to run a model on a task and evaluate its performance:
- a set of tasks, including data, tools, and simulators
- a harness for the model, with sandboxes, context management, and custom programs
- reward metrics that define success criteria
This is the key abstraction behind Lab. Environments can be used interchangeably for local development, hosted evaluations, synthetic data generation, prompt optimization, and reinforcement learning.
An environment can be a math benchmark, a code repair task, a browser workflow, a game, a customer-support simulation, an internal business process, or a long-horizon research agent.
Bring your own harness. Turn your data into training tasks. Define your own success criteria. Deploy self-improving agents.
Hosted Training
Hosted Training runs large-scale reinforcement learning in your environments. We manage the trainer nodes, rollout inference, orchestration, scheduling, auto-scaling, and weight sync.
A run is configured with a small TOML file:
model = "Qwen/Qwen3.5-0.8B"
max_steps = 100
batch_size = 128
rollouts_per_example = 8
[sampling]
max_tokens = 2048
[[env]]
id = "primeintellect/reverse-text"
Then launch it from the CLI:
prime train configs/rl/reverse-text.toml
Lab spins up a dedicated orchestrator for your run, drives rollouts through your environment, scores trajectories with your rubric, and trains a LoRA adapter with our open-source prime-rl trainer. Inference workers update as training progresses, so rollouts always come from the latest weights.
The architecture is multi-tenant across training and inference, which is what lets us price runs per token rather than per cluster-hour. You pay for the tokens that actually move the model — not for GPU time you reserved and didn't use.
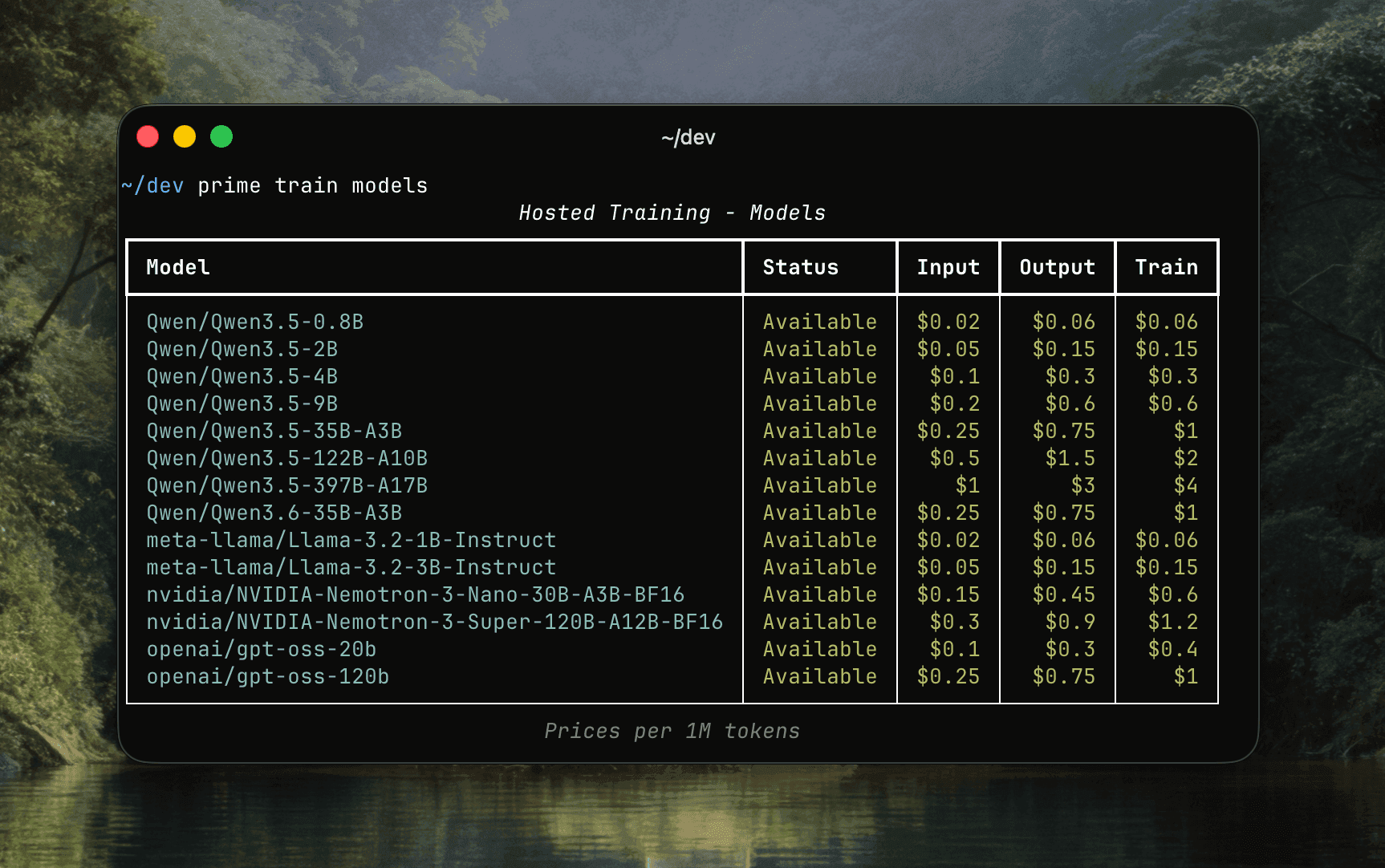
For GA, Hosted Training launches with 14 models from NVIDIA, OpenAI, Meta, and Qwen, between 1B and 70B parameters. The lineup spans dense and MoE architectures, reasoning and non-reasoning modes, text and image modalities. More providers and larger models are landing over the coming weeks.
Evaluate, Train, Inspect, Deploy
Training is only useful if it fits into an iteration loop. Lab connects each stage.
Start with a baseline evaluation. Run your environment against a base model using Prime Inference or any OpenAI-compatible endpoint. Inspect per-sample outputs, reward curves, and rubric breakdowns.
Then train. Hosted Training streams logs, metrics, reward distributions, rollout samples, checkpoints, and adapter status back to the platform. You can monitor from the dashboard or from the terminal:
prime train logs <run-id> -f
prime train metrics <run-id>
prime train rollouts <run-id>
When the run completes, deploy the trained LoRA adapter through Prime Inference:
prime deployments create <adapter-id>
Your adapter becomes available through an OpenAI-compatible API, using the same application code and SDKs you already use.
This is the loop Lab is built for: evaluate the current model, collect reward signal from real tasks, train a better adapter, deploy it, and repeat.
From Beta to GA
During beta, hundreds of users tested Lab and ran more than 10,000 training runs across research, benchmarks, games, coding environments, browser tasks, and enterprise workflows.
We also worked directly with leading enterprises and technology companies on the same question: how do you turn production work into a self-improvement flywheel?
The answer is not a generic fine-tuning job. It is a repeatable loop around your own data, tools, tasks, and reward signals. Lab gives teams the infrastructure to run that loop without rebuilding the platform stack first.
What Comes Next
Over the coming weeks, we will showcase training workflows, research directions, and real-world applications that Lab unlocks: browser and computer-use agents, long-horizon coding tasks, online evaluations, multimodal environments, prompt optimization, model distillation, and enterprise production loops.
We will also invite the community to participate directly in collaborative research efforts on the platform. Lab is part of our broader mission to build the Open Superintelligence Stack: open infrastructure, open environments, open models, and accessible training systems for the people building with them.
If you want to try Lab today, start here:
Lab is generally available now. Start training self-improving agents.