OpenDiLoCo: An Open-Source Framework for Globally Distributed Low-Communication Training
OpenDiLoCo: An Open-Source Framework for Globally Distributed Low-Communication Training
Introducing OpenDiLoCo, an open-source implementation and scaling of DeepMind’s Distributed Low-Communication (DiLoCo) method, enabling globally distributed AI model training.
Last week, we released the first step in our masterplan by launching the Prime Intellect Compute Exchange to aggregate and orchestrate global compute resources.
Today, we are thrilled to announce a major step forward on the second part by open-sourcing our distributed training framework to enable collaborative model development across globally distributed hardware.
We provide a reproducible implementation of Deepmind’s DiLoCo experiments, offering it within a scalable, decentralized training framework. We demonstrate its effectiveness by training a model across two continents and three countries, while maintaining 90-95% compute utilization. Furthermore, we scale DiLoCo to 3x the size of the original work, demonstrating its effectiveness for billion parameter models.
Paper: https://arxiv.org/abs/2407.07852
Code: https://github.com/PrimeIntellect-ai/OpenDiLoCo
OpenDiLoCo Training run visualized
Large language models have revolutionized AI, but training them traditionally requires massive, centralized compute clusters. This concentration of resources has limited who can participate in AI development and slowed the pace of innovation.
Recently, we published a detailed blog post exploring the state-of-the-art in distributed AI training. In the post, we highlight the most promising approaches and several key challenges that still need to be overcome:
- Slow interconnect bandwidth
- Ensuring fault-tolerant training
- Non-homogeneous hardware settings
- And more…
OpenDiLoCo is one of our research efforts to overcome the first of these challenges by facilitating efficient training across multiple, poorly connected devices globally.
Key Contributions
- Replication and Scaling: We have successfully reproduced the original DiLoCo experiments and extended them to the billion-parameter model scale.
- Open-Source Implementation: We are releasing a scalable implementation built on top of the Hivemind library, making decentralized training accessible to a wide range of developers and researchers. Our framework enables single DiLoCo workers to scale to hundreds of machines through our integration with PyTorch FSDP.
- Global Decentralized Training: We demonstrated OpenDiLoCo's real-world potential by training a model across two continents and three countries, achieving 90-95% compute utilization.
- Efficiency Insights: Our ablation studies provide valuable insights into the algorithm's scalability and compute efficiency, paving the way for future improvements.
DiLoCo
Recent work by Google DeepMind has introduced an approach that enables the training of language models on islands of devices that are poorly connected. This method allows for data parallel training on these different islands, requiring synchronization of pseudo gradients only every 500 steps.
DiLoCo introduces an inner-outer optimization algorithm that allows both local and global updates. Each worker independently updates its weights multiple times using a local AdamW optimizer (inner optimization). Every ~500 updates, the algorithm performs an outer optimization using the Nesterov momentum optimizer, which synchronizes all workers' pseudo gradients (the sum of all local gradients).
This approach significantly reduces the frequency of communication (up to 500 times), thus lowering the bandwidth requirements for distributed training.

OpenDiLoCo
To foster collaboration in this promising research direction to democratize AI, we have released our code for OpenDiLoCo under an open-source license: https://github.com/PrimeIntellect-ai/OpenDiLoCo.
Our implementation is built on top of the Hivemind library. Instead of using torch.distributed for the worker communication, Hivemind utilizes a distributed hash table (DHT) spread across each worker to communicate metadata and synchronize them. This DHT is implemented using the open-source libp2p project. We utilize Hivemind for inter-node communication between DiLoCo workers and PyTorch FSDP for intra-node communication within DiLoCo Workers.
Our integration with Hivemind enables a real-world decentralized training setup for DiLoCo, making many of its inherent properties usable, such as:
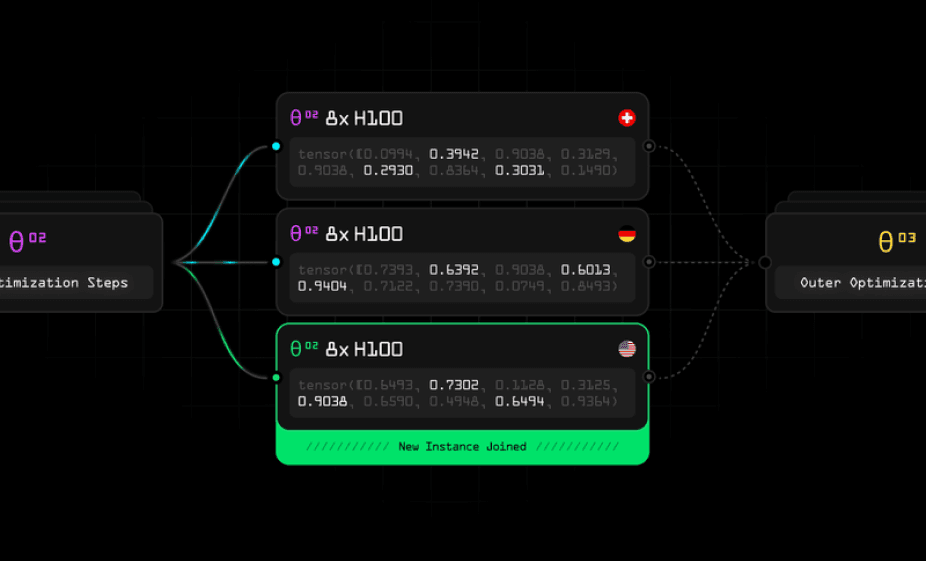
- On/Off ramping of resources: The amount of available compute can be varied during the training, with new devices and clusters joining and leaving in the middle of training.
- Fault tolerance: For decentralized training, some devices may be less reliable than others. Through Hivemind's fault-tolerant training, a device could become unavailable at any time without stopping the training process.
- Peer-to-Peer: There is no master node. All communication is done in a peer-to-peer fashion.
Main Results
As a first step, we replicated the main experimental results from DiLoCO. We trained a model with 150 million parameters on a language modeling task using the C4 dataset.
We show that DiLoCo with 8 replicas significantly outperforms the baseline without any replicas and matches the performance of a stronger baseline with the same compute budget, despite having a 500x lower communication requirement.
.png)
In addition to replicating the results, we ran several ablation studies for DiLoCo, focusing on the algorithm's scalability with the number of workers and compute efficiency. We also demonstrated that DiLoCo pseudo gradients can be effectively all-reduced in FP16 without any performance degradation.
For more details, check out the paper on arXiv.
Scaling DiLoCo to Billion Parameter Models
The original DiLoCo paper by DeepMind only experimented with model sizes of up to 400 million parameters. In our work, we scale the method to a model with 1.1 billion parameters. We adopt the same hyperparameters as TinyLlama and use a total batch size containing 8 million tokens (batch size of 8192 with sequence length of 1024). Due to the 4x larger batch size compared to our previous experiment, we decided to train up to only 44k steps for this experiment.
We compare our results against two baselines: a weak baseline without DiLoCo and without replicas, and a stronger baseline using a 4× larger batch size with data parallelism.
When using a local step size of 500 (synchronizing between workers every 500 steps), similar to the experiment with the 150 million parameter model, we observe suboptimal convergence in the early stages of training. The training dynamics improve in the later stages of training, possibly matching our baseline if we had trained further to 88k steps.
We also ran an experiment with a local step size of 125. Under this regime, the training dynamics were actually better during the early stages of training. The DiLoCo run with 125 local steps nearly matches the performance of the stronger baseline with the same compute budget, while communicating 125 times less.
.png)
While we demonstrate that DiLoCo works at the billion-parameter scale, we believe further work is needed to make it effective with larger batch sizes and increased local steps.
Globally Distributed Training Setting
To showcase the functionality of decentralized training with OpenDiLoCo across different continents, we used four DiLoCo workers, each with eight H100 GPUs, located in Canada, Finland, and two different states within the United States. The figure shows the network bandwidth between the workers, which varies between 127 to 935 Mbit/s. We trained our 1.1B parameter model with 500 local steps, and the gradients are all-reduced in FP16. Due to the large number of local steps, the four workers run independently for around 67.5 minutes before communicating for gradient averaging. For the outer optimizer step, our experiment shows an average all-reduce time between the workers of 300 seconds.
.png)
Due to DiLoCo’s significant reduction in communication time, the all-reduce bottleneck only accounts for 6.9% of the training time, minimally impacting the overall training speed.
Additional training time is spent idling by the fastest worker in our scenario. In future work, we will address this issue by exploring DiLoCo in an asynchronous setting.
Running OpenDiLoCo
Running the code is simple. The only requirement is to have access to at least two GPUs, they don’t have to be co-located. After setting up the environment, create the initial DHT node using:
python ../hivemind_source/hivemind/hivemind_cli/run_dht.py
--identity_path fixed_private_key.pem
--host_maddrs /ip4/0.0.0.0/tcp/30001
In another terminal, you can start DiLoCo workers using the command below, making sure to set PEER, NUM_DILOCO_WORKERS and WORLD_RANK appropriately:
export PEER=/ip4/192.168.100.20/tcp/30001/p2p/Qmbh7opLJxFCtY22XqwETuo6bnWqijs76YXz7D69MBWEuZ
# change the IP above to your public IP if using across nodes connected via internet
export NUM_DILOCO_WORKERS=4
export WORLD_RANK=0
torchrun --nproc_per_node=8 \
train_fsdp.py \
--per-device-train-batch-size 16 \
--total-batch-size 2048 \
--total-steps 88_000 \
--project OpenDiLoCo \
--lr 4e-4 \
--model-name-or-path PrimeIntellect/llama-1b-fresh \
--warmup-steps 1000 \
--hv.averaging_timeout 1800 \
--hv.skip_load_from_peers \
--hv.local_steps 500 \
--hv.initial-peers $PEER \
--hv.galaxy-size $NUM_DILOCO_WORKERS \
--hv.world-rank $WORLD_RANK \
--checkpoint_interval 500 \
--checkpoint-path 1b_diloco_ckpt
You can find more information about running OpenDiLoCo in the README of the GitHub repository.
Running OpenDiLoCo on the PI Compute Platform
Setting up the global orchestration layer to run a DiLoCo training run can still be quite challenging. This is made a lot easier by our PI Compute Platform thanks to our prebuilt OpenDiLoCo docker image. The image comes with all the dependencies preinstalled, allowing one to spawn DiLoCo workers with ease.

In future work, we are excited to build an integrated open-source stack into the compute platform that offers smooth solutions for orchestration across multiple clusters, efficiency optimizations, handling node failures, infrastructure monitoring, and much more.
Conclusion & Future Directions
We successfully reproduced the main experiment results of DiLoCo, scaled the method to three times the parameter size of the original work, and demonstrated its application in a real-world decentralized training setting.
For future work, we aim to scale DiLoCo to larger models on a greater number of distributed workers. A few interesting directions include model merging techniques that could improve stability and convergence speed. Additionally, compute idle time could be reduced by implementing methods that perform weight averaging communication asynchronously, interleaving them with the computation for the next outer optimization step.
We are excited about the immediate practical applications of this technique and look forward to building on it for the third part of our masterplan soon: to collaboratively train and contribute to open AI models in high-impact domains like language, agents, code, and science for collective ownership of AI models.
Join Us in Building the Open Future of AI
The power to shape the future of AI should not be concentrated in the hands of a few, but open to anyone with the ability to contribute. We invite you to join us in building a more distributed and impactful future for AI:
- If you are relentlessly ambitious and want to make this happen, apply for our open roles.
- Collaborate on our AI model initiatives and open-source frameworks.
- Contribute compute & earn ownership in state-of-the-art AI models.
Our OpenDiLoCo work has also been accepted at the ES-FoMo workshop at ICML. Reach out if you’re coming to Vienna!