SYNTHETIC-1: Scaling Distributed Synthetic Data Generation for Verified Reasoning
SYNTHETIC-1: Scaling Distributed Synthetic Data Generation for Verified Reasoning
Today, we are excited to introduce SYNTHETIC-1, a collaborative effort to create the largest open-source dataset of verified reasoning traces for math, coding and science, leveraging DeepSeek-R1. Our dataset consists of 1.4 million high-quality tasks and verifiers, designed to advance reasoning model training.
We invite everyone to contribute compute and join us in our effort to scale distributed reinforcement learning to o3-scale and beyond.
In our recent post, Distributed Training in the Inference-Time-Compute Paradigm, we explored how this paradigm shift will fundamentally reshape compute infrastructure, making globally distributed training the way forward.
The DeepSeek-R1 paper highlights the importance of generating cold-start synthetic data for RL. As our first step toward state-of-the-art reasoning models, SYNTHETIC-1 generates verified reasoning traces across math, coding, and science using DeepSeek-R1.
Our Contributions
-
SYNTHETIC-1: Reasoning Dataset & Public Run: We are releasing our dataset of 1.4 million high-quality tasks and verifiers and are allowing anyone to contribute compute to our synthetic data generation run.
-
GENESYS: Synthetic Data Generation Framework easily extendable open-source library for synthetic data generation and verification and a call for crowdsourcing tasks & verifiers.
The Road to Fully Open-Source Reasoning Models
With the release of Deepseek-R1 and our own INTELLECT-MATH model, we have gained new insights into training state-of-the-art reasoning models such as o1.
The DeepSeek team first trained DeepSeek-R1-Zero entirely via reinforcement learning, using Group Relative Policy Optimization (GRPO) from DeepSeek v3. They then used R1-Zero to generate cold-start long Chain-of-Thought reasoning data to fine-tune DeepSeek v3. Finally, they applied GRPO training again on the resulting SFT model, producing the stronger DeepSeek-R1 model.
Key Findings from DeepSeek-R1:
- Cold-start data for SFT significantly improves model performance, making R1 much stronger than R1-Zero.
- Distillation from a strong teacher model is highly effective, even without additional RL. Whereas smaller models relying on the large-scale RL mentioned in this paper require enormous computational power and may not even achieve the performance of distillation.
Our Next Steps:
Therefore, our open reproduction and scaling of R1 will proceed in two steps, closely mirroring the DeepSeek-R1 approach:
-
Generate Verified Reasoning Data
- Create the largest dataset of verified reasoning traces across math, coding, and science.
- Open-source these datasets to enable stronger, smaller reasoning models.
📌 DeepSeek trained on only 800k samples for distillation; by scaling verified reasoning chains, we can likely achieve even better models.
-
Globally Distributed Reinforcement Learning with Verifiable Rewards
- Train SFT models further using reinforcement learning with verifiable rewards.
- Conduct this training in a globally distributed setting, allowing anyone to contribute compute.

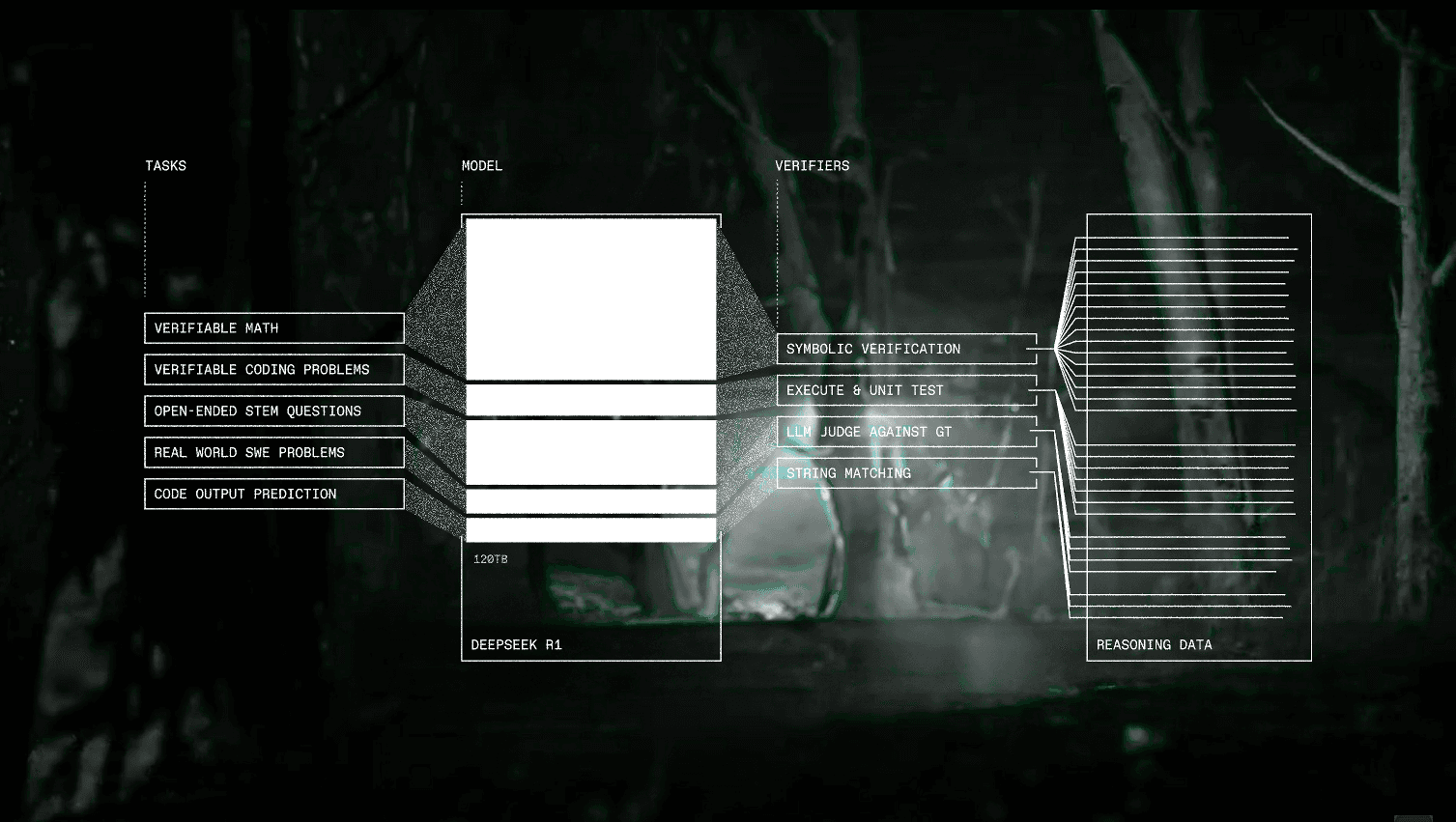
SYNTHETIC-1 Tasks & Verifiers
SYNTHETIC-1 consists of 1.4M curated tasks spanning math, coding, software engineering, STEM, and synthetic code understanding. It includes both programmatically verifiable problems (e.g., coding tasks with unit tests) and open-ended reasoning challenges verified using LLM judges. We also introduce a novel recipe to generate synthetic code understanding tasks that are highly challenging for state-of-the art LLMs.
777k Verifiable Math Problems:
To collect verifiable math problems, we use the NuminaMath dataset consisting of mostly high school competition level mathematics questions. We apply LLM-based filtering on top of the data to remove questions that are not automatically verifiable (e.g. questions asking for proofs) and to rewrite multiple-choice questions into a direct question-answer format.
144k Verifiable Coding Problems
We aggregate coding problems along with unit tests from the publicly available Apps, Codecontests, Codeforces and TACO datasets. Since most problems were available for python only, we rewrote them for Javascript, Rust and C++ to go from ~36k problems to ~144k. To verify LLM responses, we use containerized execution environments implemented in our library genesys.
70k Real-World Software Engineering Problems
We process CommitPack, a dataset of real-world Github commits, to curate a set of 70k open-ended software engineering problems. A single task instruction consists of a code file before a commit and an LLM-generated instruction to modify the code - this instruction is synthesized with an LLM that has access to the original commit message and the post-commit state of the file. To score solutions, we use an LLM judge that compares the given solution to the actual state of the file after the commit.
313k Open-Ended STEM Questions
We use the StackExchange dataset to collect questions from a wide range of technical & scientific domains. We apply LLM-based filtering to only select questions that have objectively correct responses (e.g. we filter out questions that explicitly ask for opinions) and that require reasoning rather than just retrieving information. Similar to our software engineering problems, we score responses by using an LLM judge that has access to the most upvoted response to a question.
61k Synthetic Code Understanding Tasks
We propose Synthetic Code Understanding, a task that is highly challenging for state of the art LLMs and can be generated in a fully automated manner without human annotators. The objective of this task is to predict the output of code that applies arbitrary transformations to a string given some test input. To generate task data, we prompt LLMs to generate arbitrary string processing functions and recursively make them more complex using a prompting scheme similar to evol-instruct.
To obtain inputs, we generate both random strings and select snippets from news articles, and feed them through the LLM-generated code to obtain ground truth outputs. To verify a predicted output, we can simply check if the predicted output string matches the ground truth string.
For long input strings and many iterations of making the code more complex, even o1 has a near-0% solve rate on this task. Our final dataset consists of 61k problems of varying complexity for Python, Javascript, Rust and C++.

GENESYS
Genesys is our open-source library for synthetic data generation and verification that powers the release of SYNTHETIC-1. It contains efficient implementations of verifiers such as LLM judges and containerized code execution environments that run asynchronously, making it ideal for both synthetic data generation and particularly also reinforcement learning.
Genesys is designed to be easily extendable: You can generate responses for your own tasks by using a Hugging Face dataset with with our flexible schema, and add your own verifier with minimal implementation effort. Instructions for this can be found in our README.
We agree with Karpathy: one of the most impactful things the open-source community can do is to crowdsource tasks & verifier environments. Great examples of such environments include KernelBench, which evaluates an LLMs’ ability to write efficient GPU kernels, as well as SWE-Gym, which tests LLMs on real world software engineering tasks.
Get involved: Contribute to our open-source codebase, and reach out on Discord if you’d like to add high-quality tasks and verifiers to our ongoing SYNTHETIC-1 run.
How To Contribute Compute
Anyone can now contribute resources to advance open-source AI through our platform and later on also in a distributed way with their own hardware.
Dashboard: https://app.primeintellect.ai/intelligence (watch the run and contribute compute)
Our recent work on TOPLOC, which enables verifiable inference through a locality-sensitive hashing scheme, will serve as the foundation for distributed compute contributions.

Conclusion and Next Steps: Scaling to the Frontier
SYNTHETIC-1 is just the first step towards scaling to state-of-the-art open reasoning models.
We are looking forward to community contributions in the form of compute, code or data to create the largest open reasoning dataset to date.
Furthermore, we are currently extending our training framework prime to support globally distributed reinforcement learning as the next step in our plan.
If this sounds exciting to you, join us. We are a small, talent-dense and highly ambitious team and are looking for engineers and researchers to help us build open source AGI.