TOPLOC: A Locality Sensitive Hashing Scheme for Trustless Verifiable Inference
TOPLOC - A Locality Sensitive Hashing Scheme for Trustless Verifiable Inference
We introduce TOPLOC, a novel method for verifiable inference. TOPLOC employs a compact locality sensitive hashing mechanism for intermediate activations, which can detect unauthorized modifications to models, prompts, or compute precision with 100% accuracy in our empirical evaluations.
The system maintains robustness across diverse hardware configurations, GPU types, tensor parallel dimensions, and attention kernel implementations, while achieving validation speeds up to 100× faster than the original inference.
The polynomial encoding scheme used in TOPLOC reduces the memory overhead of generated commits by 1000×, requiring only 258 bytes of storage per 32 new tokens compared to the 262 KB required for storing token embeddings directly for Llama-3.1-8B-Instruct. This makes TOPLOC a practical solution for large-scale deployment.
TOPLOC is easy to implement in modern inference engines and efficient enough to generate commits for all model inferences performed by an untrusted compute provider with minimal overhead.
By enabling efficient verification of LLM inference computations, TOPLOC establishes a foundation for building an open and distributed AI system.
ICML 2025 Poster: https://icml.cc/virtual/2025/poster/46281
Paper: https://arxiv.org/abs/2501.16007
The Problem: Trust in LLM Inference
Inference providers often make adjustments to computation methods to optimize for cost, efficiency, or specific commercial goals. While these modifications can make inference more economical and scalable, they may also impact the quality, accuracy, and transparency of the service provided to users.
- Lower precision: Inference providers might use lower precision formats which reduces compute and memory requirements.
- KVCache compression: To enable faster and longer generations, providers may compress intermediate tensors.
- Model Weight Alterations: Providers may distill, merge, or prune weights to reduce compute and memory requirements.
- Altered prompt: Providers could modify the system prompt to align with their commercial goals, incorporate specific biases, or prioritize certain outcomes.
TOPLOC
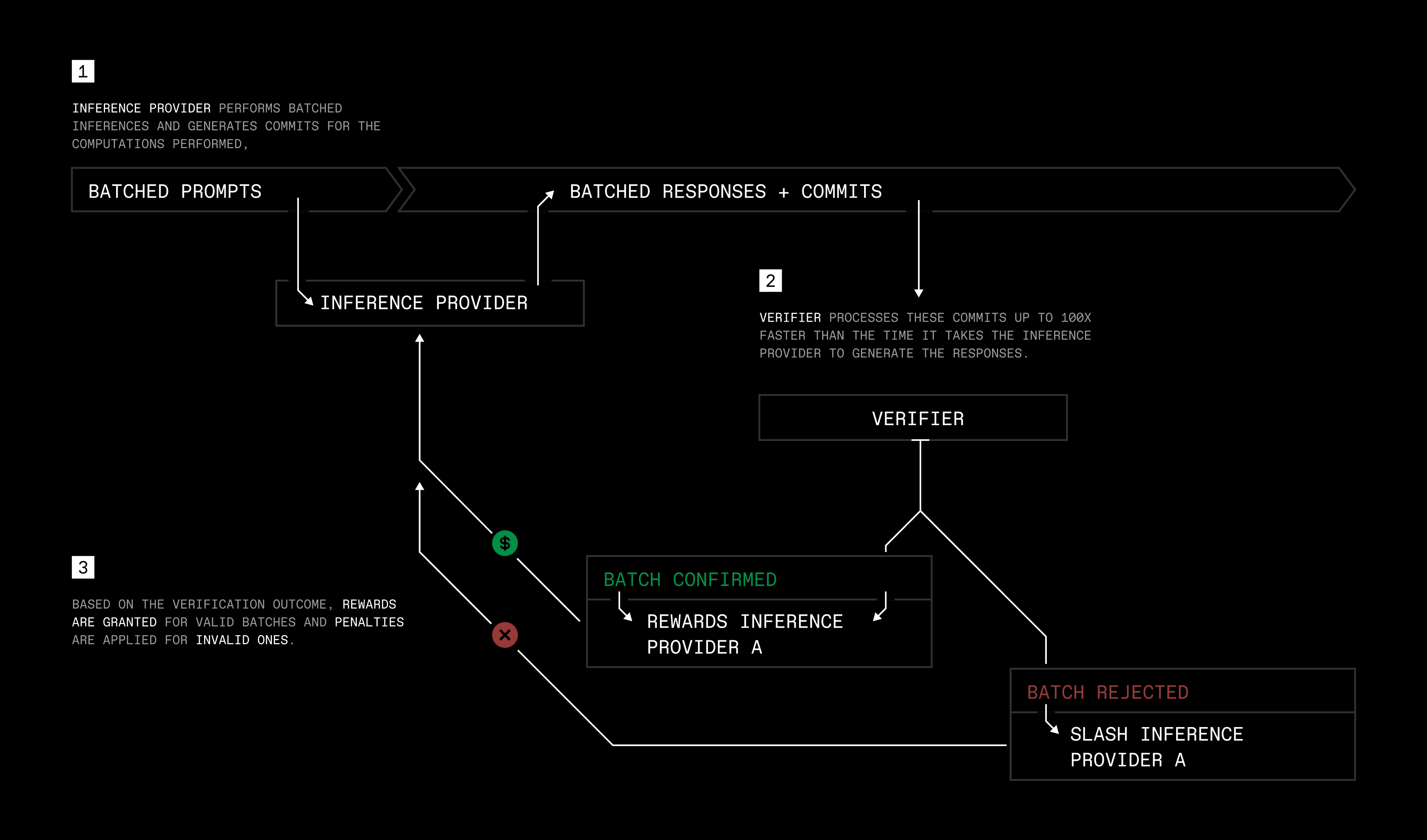
The TOPLOC algorithm encodes and validates the most salient features of the last hidden state tensor using a compact, verifiable proof. During the generation phase, the inference provider commits to the top-k values in the last hidden state, which can later be verified by the validator by recomputing the last hidden states. Due to increased parallelization, the validation can be done a lot faster than the original generation. Because the last hidden state depends on previous ones, verifying the correctness of the last hidden state gives us confidence that the previous hidden states are correct as well.

During proof generation, the top-k indices and values are extracted from the tensor, and an injective modulus m is computed to uniquely map these indices. The indices and theircorresponding values are encoded into a polynomial, which, along with the modulus, forms the proof.

For validation, the proof is decoded to retrieve k, m, and the polynomial. The top-k features are recalculated and compared against the proof by checking for differences in the exponent and mantissa. Validation succeeds if all error thresholds are not exceeded.

Robustness across Different GPUs, Attention and Tensor Parallel Implementations
Why do we need to go through the trouble of measuring error rate and using thresholds? Since both computations are the same algebraically, can we not just directly take the equality of the resulting tensors?
We could if computers performed real number arithmetic precisely and deterministically. However, modern computers, with their digital limitations, perform arithmetic on real numbers using floating point arithmetic. Floating point arithmetic is sensitive to the order of computations — a + b + c does not always equal c + b + a. Because of this, algebraically reordering the computation, despite theoretically yielding equivalent results does not yield equivalent results in practice.
Algebraic reorderings of the computation can occur on GPUs for all sorts of reasons: different CUDA version, different GPU models, different tensor parallel configurations, kernel implementations and even just seemingly randomly at the whims of the GPUs scheduler. Rewriting the computation to increase parallelization and make the validation faster changes the order of computation and might even change the cuBLAS kernel that is used for the matrix multiplications.
This reordering becomes a big issue when it changes where catastrophic cancellations occur in the computation. Catastrophic cancellation occurs as a result of the addition of two floating point number of opposite sign that are very close in magnitude. Because bf16 only has 7 bits of precision, these cancellations can often lead to the appearance of exact zeros. Depending on the order of the operations, the location of these exact zeros will be affected.
Interestingly, this behaviour reveals a notable property: small values are more susceptible to rounding errors, whereas larger values tend to be represented consistently after algebraic reordering. This insight motivates us to focus on the larger values in a tensor when designing our hash function. By prioritizing these large values, we can reduce the impact of rounding errors and improve the robustness of the hash function.
Another notable property is that the difference in the mantissa when the exponents match is likely to be small. A mismatch in exponents after an algebraic reordering indicates that the sum is on the edge of overflowing in the precision and incrementing the exponent. The overflowed mantissa is likely very different from the non-overflowed mantissa. In our experiments, we found that the deviations in the mantissa are small when the exponent bits are matched, making the mantissa deviations a suitable threshold given we only take the difference when the exponents match.

In our experiments, we found a set of thresholds that are robust across different GPUs, attention and tensor parallel implementations while still being able to distinguishes different models, prompts and compute precision. More details on these experiments can be found in our paper.
Integration into Popular LLM Inference Engines
We provide a straightforward implementation of TOPLOC integrated with vLLM for efficient inference and validation: https://github.com/PrimeIntellect-ai/toploc.
Additionally, we maintain a fork of SGLang that includes a TOPLOC integration, enabling verifiable inference within SGLang's framework.
Challenges and Future Directions
Although TOPLOC is a significant leap in verifiable inference compared to existing methods, there still remains unsolved problems, challenges and future directions that could further improve the coverage and widespread use of TOPLOC for verifiable model computation:
- Extending to model training: Currently, we have only explored using TOPLOC to verify LLM inference. The method could however also be extended to verify distributed model training. Similar to inference, model training is non-deterministic due to GPU scheduling. Small perturbations in one step of the gradient descent changes the gradients for subsequent steps, leading to cascading differences. This cascading also occurs for LLM inference because the non-determinism will change the contents of the KV-cache, altering subsequent computation. It would be interesting to explore whether our method’s robustness to cascading differences in the KV-cache can also extend to stochastic gradient descent.
- Extending to different modalities and pipelines: The current work only explores LLM inference on text. However, there are many other types of model inferencing people are interested in verifying. For example, we could extend the method to verify computation for multi-modal language models and stable diffusion text to image pipelines. As long as we have an activation tensor that is dependent on all previous activations and is theoretically deterministic (does not make any calls to a random number generator), we can apply TOPLOC to verify the computation.
- Speculative decoding and sampling: Our method is currently not capable of detecting speculative decoding, which requires inspecting the execution of the sampling algorithm.
- Unstable prompt mining: Inference consumers may attempt to exploit the system by mining for prompts that deliberately increase the likelihood of validation failure. Ensuring that the method is resistant to such attacks remains an important consideration for widespread use of TOPLOC for verifying inference computations.
Why TOPLOC Matters
Verifying model inference is a critical component in building peer to peer AI. By enabling inference verification, users can trust inference providers and audit model changes that may impact downstream systems. As AI-powered agents become a larger part of the software stack, the demand for verifiable on-chain inference will continue to grow.
To date, most efforts in this area have focused on generating Zero-Knowledge (ZK) proofs for model inference. However, we believe this approach is unlikely to achieve practical adoption in the near future. ZK proof generation and validation methods are currently too computationally expensive and slow. Even under optimistic assumptions about advancements in ZK methods, the cost of generating ZK proofs for inference would still be 100× higher than the original inference computation.
A more practical approach is to use recomputation to secure the system. Recomputation also integrates seamlessly with cutting-edge model inference engines, which would be a challenge for ZK solutions to integrate.
The use of recomputing intermediate activations to verify the integrity of trustless compute has been explored in works like arXiv:2405.00295 and arXiv:2406.00586. However, these methods require the computations to be deterministic, making them unsuitable for handling hardware non-determinism. Additionally, they cannot take advantage of algebraic shortcuts in validation, such as the ones we propose.
Advantages of TOPLOC
- 100% detection accuracy for unauthorized modifications in our experiments.
- Robust across diverse GPU and tensor parallel configurations.
- Faster validation speeds than generation (up to 100×).
- Over 1000x memory efficiency compared to directly storing the last hidden layer values.
Conclusion
As LLMs continue to become more integral to the modern computing stack, ensuring the integrity and trustworthiness of inference providers becomes increasingly critical. TOPLOC represents a significant advancement in addressing this challenge by providing a practical, efficient, and robust solution for verifiable inference.
TOPLOC achieves this through several key innovations:
- A novel locality sensitive hashing mechanism that can detect unauthorized modifications to models, prompts, or precision with perfect accuracy that is robust across different hardware configurations, GPU types, and computational reorderings.
- A validation approach that leverages algebraic rewrite to achieve a validation speed of up to 100× the original generation.
- A polynomial encoding scheme that reduces proof storage overhead by 1000×
Unlike existing approaches such as ZK proofs which incur prohibitive computational overhead, TOPLOC's introduces negligible overhead to the inference provider. This efficiency, combined with its seamless integration capabilities with modern inference engines, positions TOPLOC as a viable solution for widespread adoption in peer to peer AI.
TOPLOC enables the development of truly open distributed AI where users can trust inference providers by default. This foundation of trust is crucial for the emerging ecosystem of autonomous AI and agentic commerce.
Outlook
For our launch of INTELLECT-MATH last week, focusing on our first reasoning and synthetic data release, we provided an outlook on distributed training within the inference-compute paradigm: The inherently parallel nature of synthetic data generation as well as reinforcement learning makes it particularly well-suited for a globally distributed setting. Workers can operate independently, each focusing on their own generation tasks under the supervision of a verifier, without requiring frequent direct communication between them, offering significant scalability advantages.
However, this distributed setting presents a critical challenge: How can we ensure that workers are performing inference correctly? What if they secretly substitute the model with a smaller one to reduce costs? Or worse, what if they insert hidden tokens into the prompt to bias the generations?
With the release of TOPLOC, we are one step closer to addressing these trust challenges and are excited to leverage it in our early experiments in the coming weeks.