True Agents Model the World

True Agents Model the World
Pretraining creates simulators, LLMs that can model their environment with high precision. RL only improves the model’s own generations.
But true agents should do both at the same time: we don’t want a pure simulator, but neither do we want the LLM to only act, blind to how it will affect its environment. Instead, we want it to learn to predict its environment in response to its own actions, allowing it to more intelligently plan and respond to unexpected world dynamics. Synthetic data during pre- and midtraining achieves similar objectives, but only world modeling during RL is truly on policy.
Recent work (ECHO and PaW) captures these benefits by combining RL on the assistant tokens with SFT on the tool response tokens. By restating SFT as RL with constant positive advantage, this can be implemented at no additional cost. In this article, we present early results from our own work on world modeling during RL.
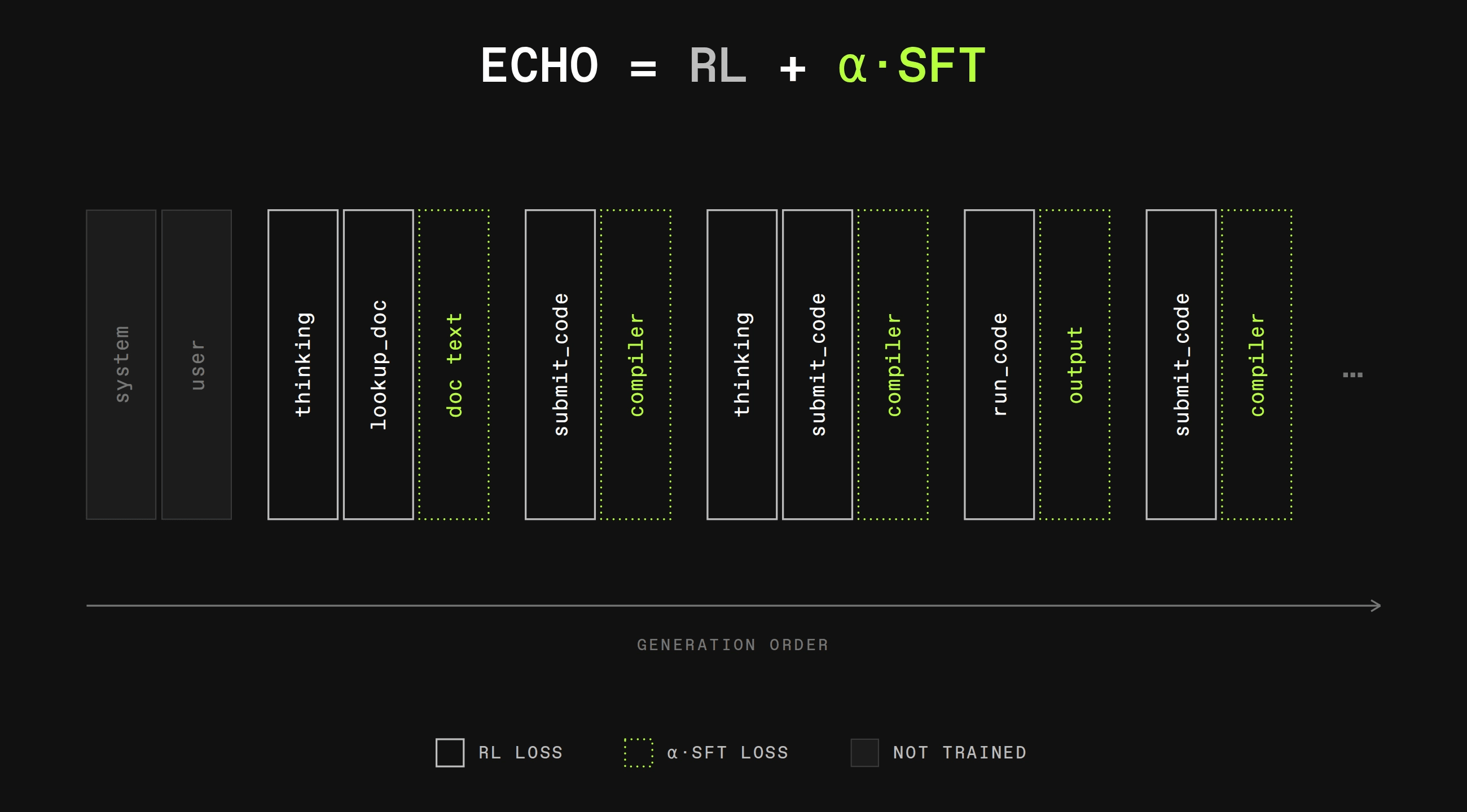
Setup
We started our work with a set of hypotheses that we wanted to test.
- World modeling during RL will make learning faster and more efficient
- This will be especially true on domains not encountered much during pre- and mid-training
- World modeling works best under two conditions:
- The tool outputs are predictable without memorization. That’s because it both shows and drives generalization
- The tool response is complex. That way, there’s something to learn and less chance of collapse to producing trivial outputs only
- SFT on purely knowledge based tool outputs, like a search through documentation, makes the model internalize the knowledge more deeply than directly training on the documentation
- The Cartridges paper showed that in order to internalize a piece of knowledge, it is better to re-formulate it into a Q&A dataset and training on that than to train directly on the document
- We hypothesize that training on the output of search through documentation during a real rollout has a similar effect: Cartridges presents the same information in the context of different questions, world modeling on documentation presents the same information in the context of different tasks and call to specific code
To test these, we separately trained on two different environments.
forth-lang
forth-lang is an environment for the under-resourced programming language forth. We chose it because it’s predictable but complex, and models don’t know it well. For an example, see this link.
We wanted to set the environment up in a way that forces the model to actually call the code and predict how it behaves under different inputs.
To achieve that, we don’t give the model access to the test cases, even though they are used to determine the reward. We ensure this by running each rollout in a dedicated sandbox, and only uploading the tests after the rollout has finished. This forces the model to not only cover the inputs used in the tests, but to generalize to all possible inputs, and to evaluate its own code not by running tests but by actually running the code.
The following tools are available:
submit_code: Submit code. The compiler output is returned directly to the model unedited, including any errors. When the rollout finishes, the last submitted code is used as the model’s final answerrun_code: The last submitted code is run, with model-provided inputs if there are any. Returns the raw output of the code, including error messages. This way, the model can test the code however it wants tolookup_doc: Search in the official forth documentation, baked into the custom Docker image on each sandbox. How the search works:- If there’s only one word in the search query, the tool tries to find an entry named after the search term and will return it
- If none is found, or the query contains multiple words, BM25 search is performed using bm25s; all results with a similarity <1.0 are filtered out from the candidate pool, and the top 3 results are returned
- If no such result exists, a suggested similar query that would yield a result is returned
submit_code and run_code represent highly predictable but complex environment dynamics. lookup_doc is much simpler, which made us suspect that training on its outputs would weaken the model. On the other hand, each piece of documentation is so directly relevant to the task at hand that it might also be helpful. To get certainty, we performed ablations comparing training only on the former two tools, which we call ECHO (code), with training on all three, which we call ECHO (all).
deepdive
The second environment we experiment on is deepdive: a web-search Q&A environment we use for training deep research. It offers the following tools:
search_web: Uses Serper to search the web. Takes a list of queries, runs searches in parallel, and returns the results in the same order. In past runs, this was the tool used the most by farscan_page: Loads a URL’s contents and returns metadata about it (errors, size, etc.) Optionally takes regular expressions as search terms. Any content line that contains a result is displayed with a line numberopen_lines: Loads a URL’s contents and displays it. Optionally, a line range can be passed to filter the results down to only the lines surrounding some search result, and save on context. Shares a cache withscan_pagefinish: end the rollout with the final answer as the argument tofinish
We chose this environment because its environment dynamics are simple: enter a query, get web results back. On the other hand, the web results themselves are very difficult to predict, and because predicting them mostly requires memorization, we expected that it doesn’t transfer to new tasks that need different knowledge.
One confounding factor that we need to mention is that in practice, the number of queries and search results used in a deepdive training run are limited, so it’s possible that training on the search results are directly useful to subsequent tasks, even if it doesn’t generalize well. We control for this with a deepdive test set.
Online evals
We perform online-evals throughout the runs, on the following environments:
forth-langtest setdeepdivetest setwordle: used as a logical multi-turn environment with simple tools. requires predicting the results of the tool calls, since it’s not possible to guess over and over againgeneral-agent: a tool-heavy environment that sits between wordle and deepdive on the logic-retrieval axis, introduced in our recent blog
This diversity of evaluation environments will let us know if and how world modeling in a training environment generalizes to other environments.
Algorithm
SFT on tool outputs is performed without significant additional cost: in normal RL, we mask out all tokens from the loss except for the ones that the model itself produced. This is equivalent to providing a non-zero advantage to model tokens and zero advantage to all other tokens. We simply use alpha, the user-provided parameter determining the strength of SFT, and set it as the advantage on the SFT tokens. It’s always positive and always the same for all tokens. This allows us to use the same forward and backward pass as RL to compute the SFT loss.
We skip RL-specific steps:
- We don’t use a KL loss between trainer and inference
- We don’t use an importance ratio
- We don’t mask tokens icepop-style
They aren’t needed for SFT, only for RL.
Like in RL training, we normalize by the total number of tokens in the training batch, to make the updates batch invariant. However, we do this independently for RL and SFT tokens so that one doesn’t drown out the other just by virtue of providing more tokens.
Experiments and Results
In our experiments, we truncate when rollouts exceed 32,768 tokens. The maximum tokens generated per turn is 8192. We perform full parameter finetuning with a constant learning rate of 1e-6 on Muon unless specified otherwise. Our total batch size and group size vary between experiments.
We will first present our experiments on forth-lang, as those are our main results, then follow up with deepdive.
For forth-lang, we ran multiple sets of experiments. Because we ran these experiments while actively developing the environment, different sets of experiments used different versions of forth-lang. We will mark them accordingly. The experiments will be presented from newest to oldest, because the newest results are the most meaningful — they ran on the newest version of the environment, and were performed with the lessons from previous runs in mind. Older experiments serve as supporting evidence.
As a reminder, we also sometimes trained with all tools: ECHO (all) and sometimes with only the two code tools: ECHO (code) in forth-lang.
Ablating alpha
Early on, we performed a quick ablation on both forth-lang and deepdive using Qwen3-4B-Instruct-2507, sweeping alpha over {0.01, 0.05, 0.1, 0.5, 1.0}, for 100 steps without evals. We noticed little difference in the training reward of either, though 0.05 and 1.0 seemed the best by a small margin. We expect this to be random noise but nevertheless kept these values in mind.
forth-lang GLM-4.5-Air
We performed experiments with GLM-4.5-Air, a 106 billion total and 12 billion active parameter model. They were run at a total batch size of 128 with a group size of 16 (8 prompts per batch). These experiments were run with signSGD as the optimizer.
Based on the ablation above, we initially picked alpha=0.05 to be conservative. However, we quickly discovered that ECHO (code) shows signs of collapse after ~50 steps, and just kept getting worse and worse:
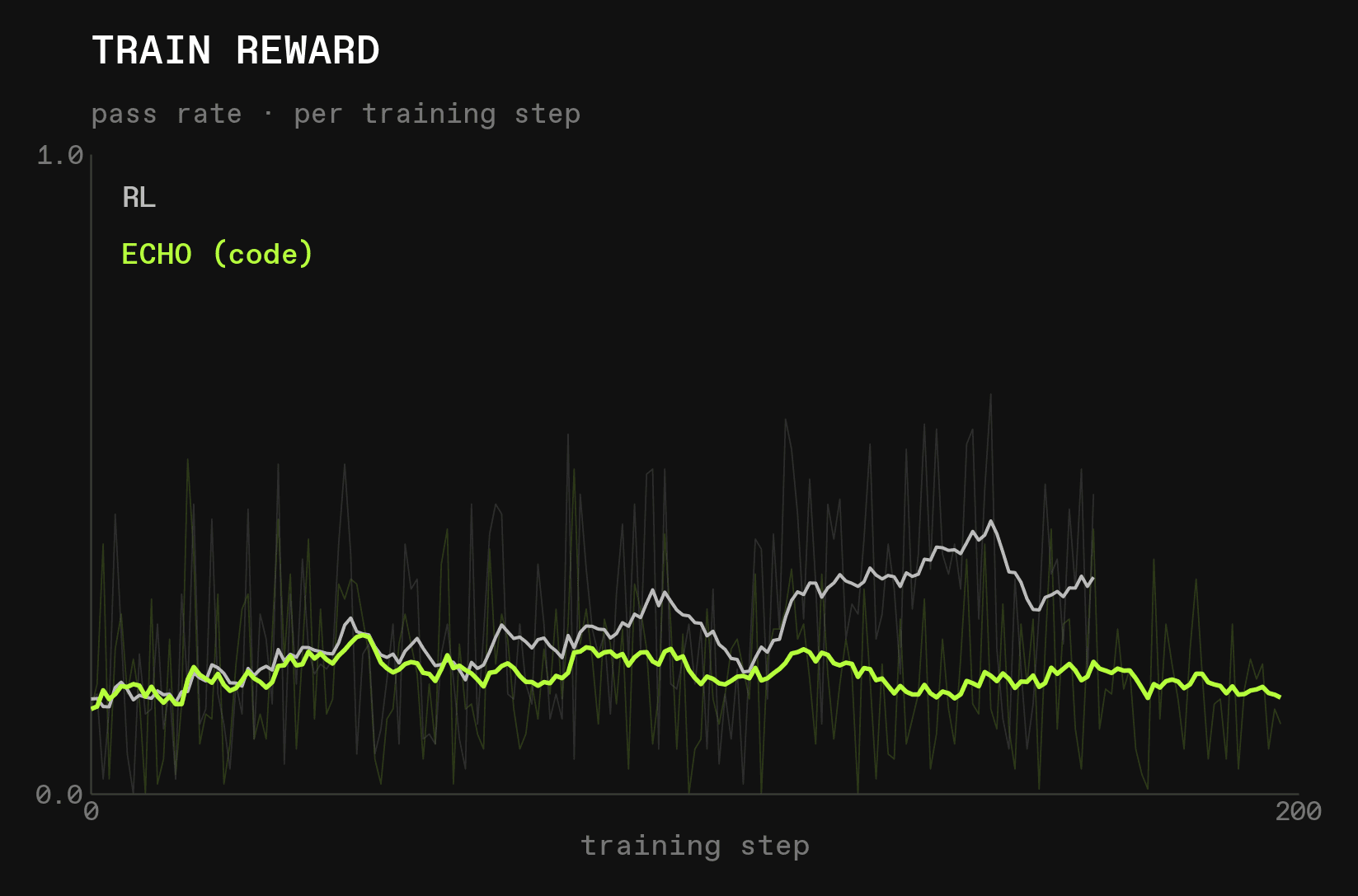
Interestingly, ECHO (code) only suffered on forth-lang evals, not on any of the others:
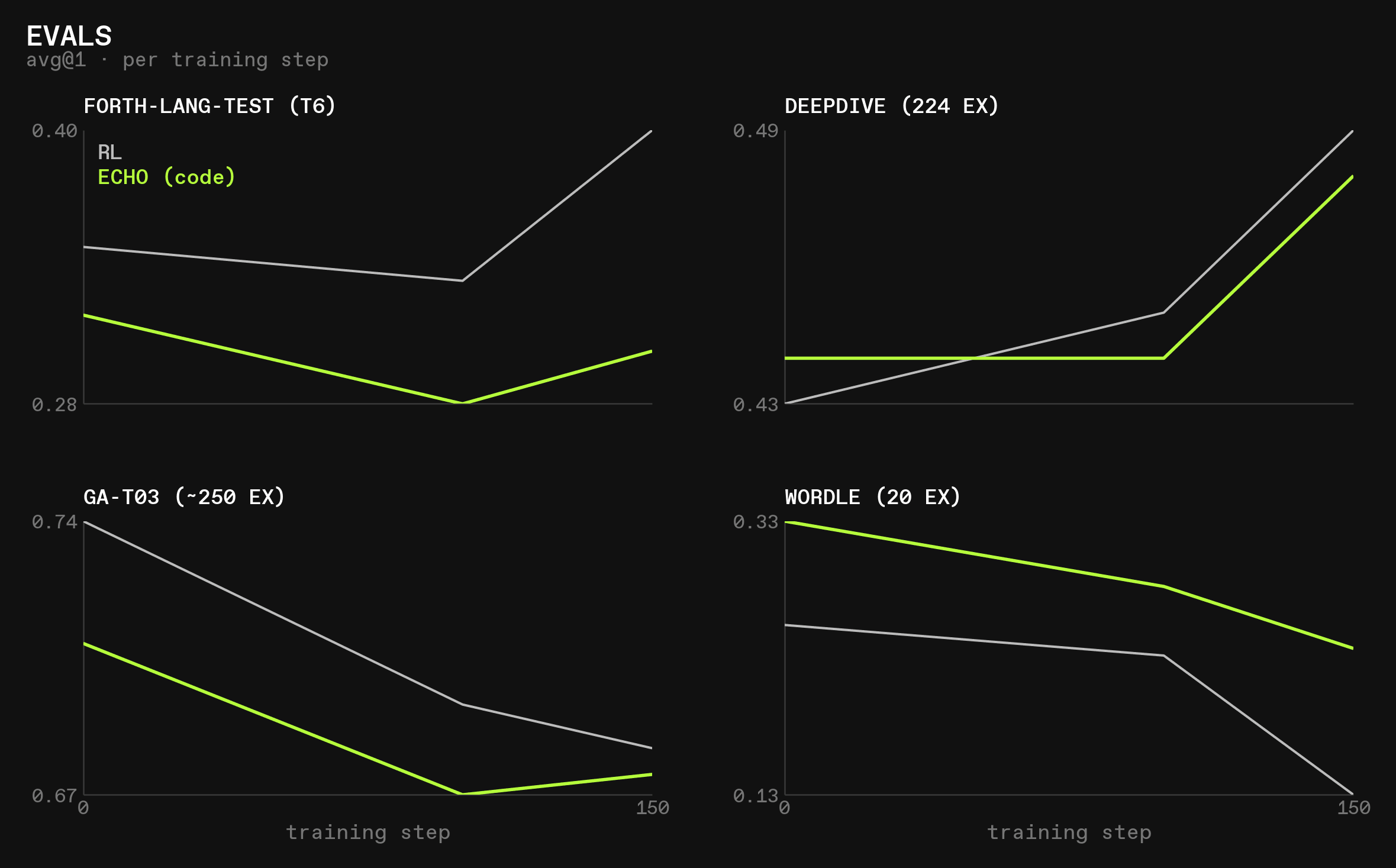
Still, this was a negative result.
Since pure RL (alpha=0.0) was so much stronger than ECHO (code), we next tried reducing alpha by a factor of 10 to 0.005 and saw much stronger results. Note that we have fewer datapoints for RL than for ECHO (code) because the former used more turns per rollout and was thus much slower, and we let both run for the same amount of time.
The results were initially very positive. Reward looked similar between the two settings:
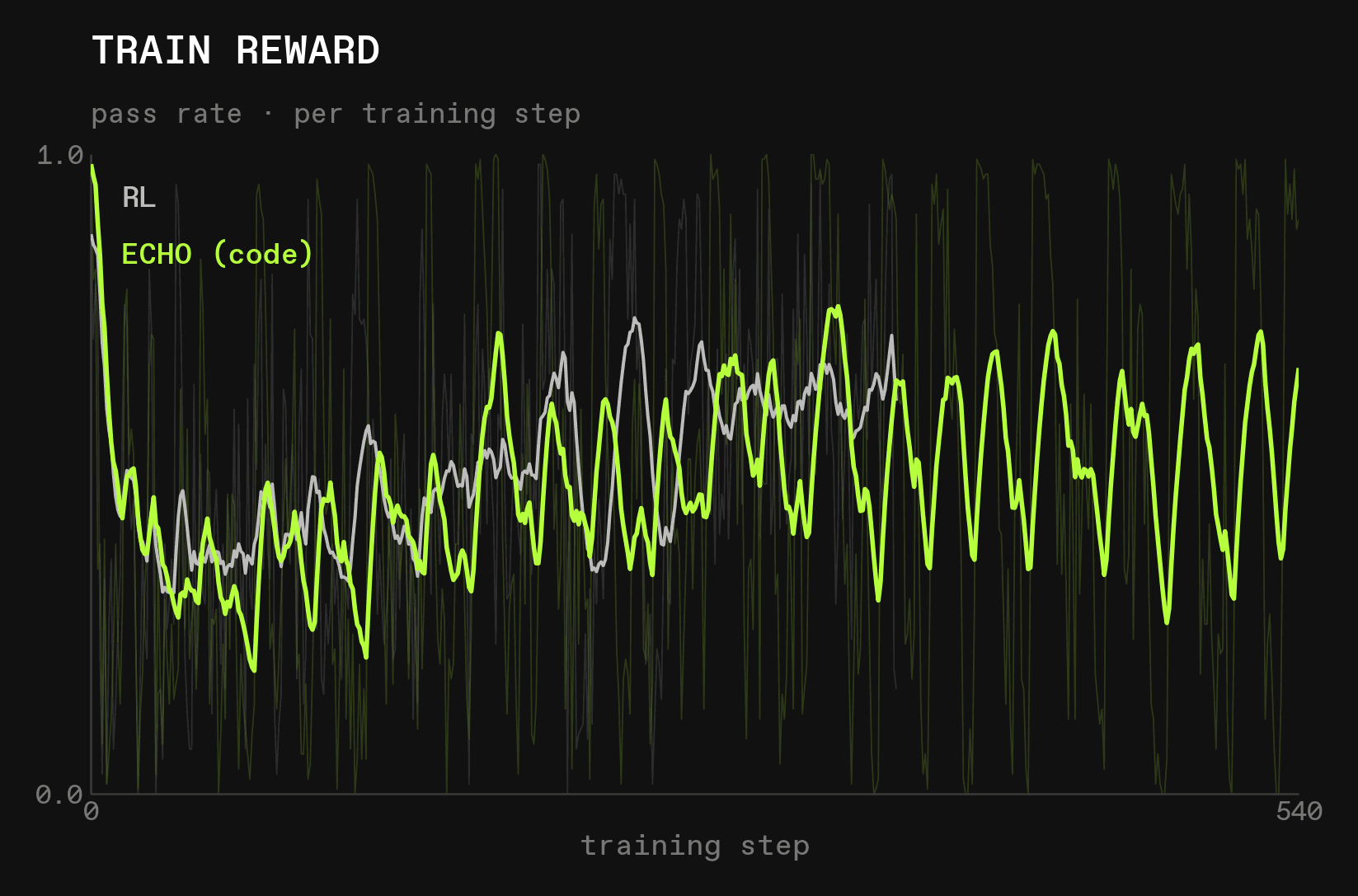
At the same time, ECHO (code) had a lower submit_code error rate, used slightly fewer turns, and got truncated less often:
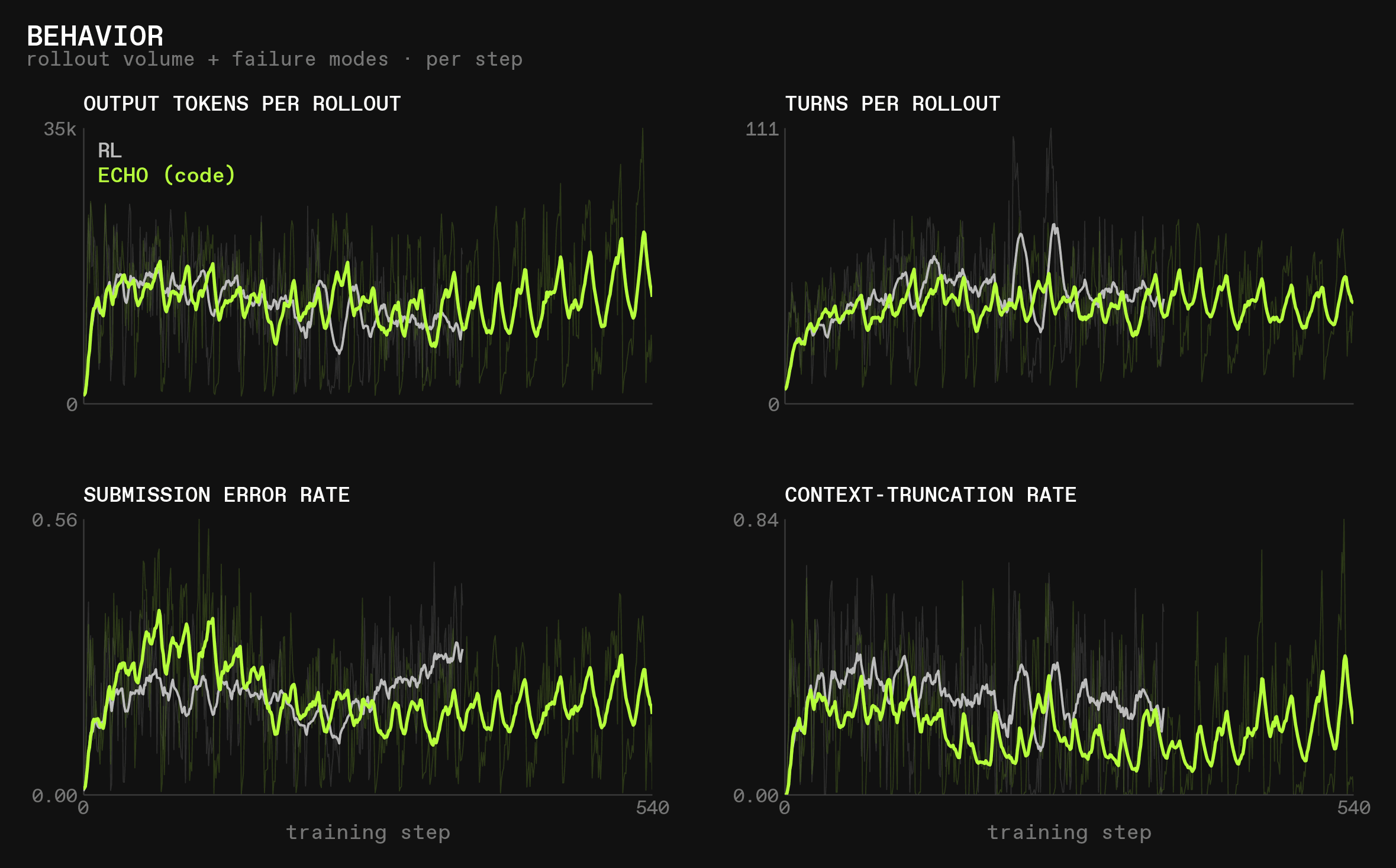
Notably, evals for forth-lang were significantly better than for RL most of the time but after around 500 steps, forth-lang evals started to suddenly drop:
We see two possible explanations for this behavior:
- A random crash
- The model started overfitting on the training set
The latter is not unlikely: With 419 prompts, 500 steps at 8 prompts per step means almost 10 epochs on the same data. For pure RL, this isn’t a big issue, but when a loss with much higher signal density is introduced, that might no longer be true.
Either way, before the crash, ECHO (code) seems to have consistently outperformed pure RL in forth-lang evals, without suffering in other environments, for 10 full epochs. And even the potential overfitting is limited to forth-lang! All this was achieved at a slightly but consistently lower number of turns than pure RL. Additionally, it is unclear whether or not RL would have stayed stable for longer, though we assume it would have (the drop in eval performance we see at the end isn’t abnormal and no reason to conclude early collapse).
One interesting datapoint is that ECHO (code) learns to predict the outputs of submit_code and run_code exceptionally well:
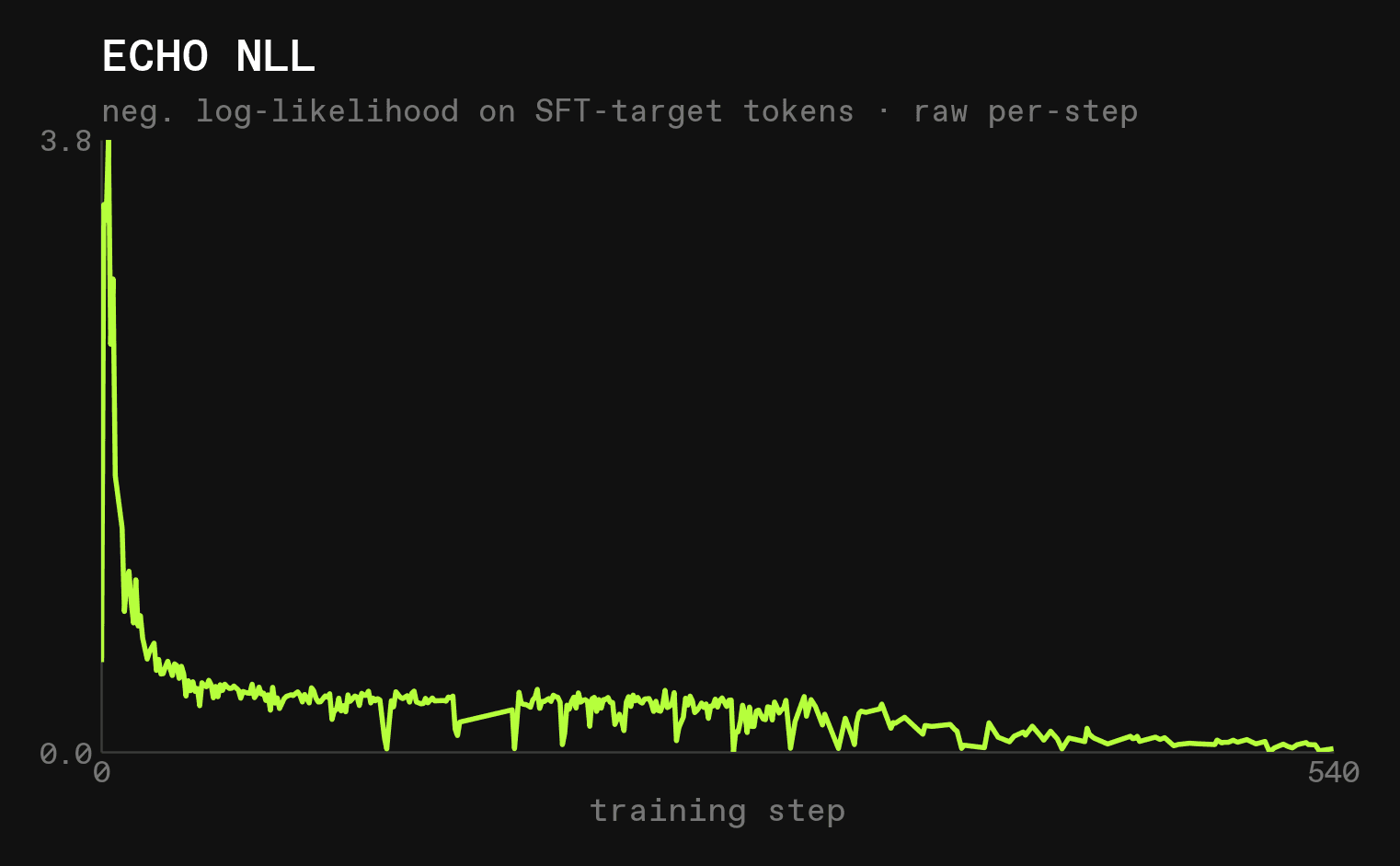
This is both another sign of overfitting, and a sign that ECHO in small doses works as intended.
Behaviorally, ECHO (code) has a strong impact:
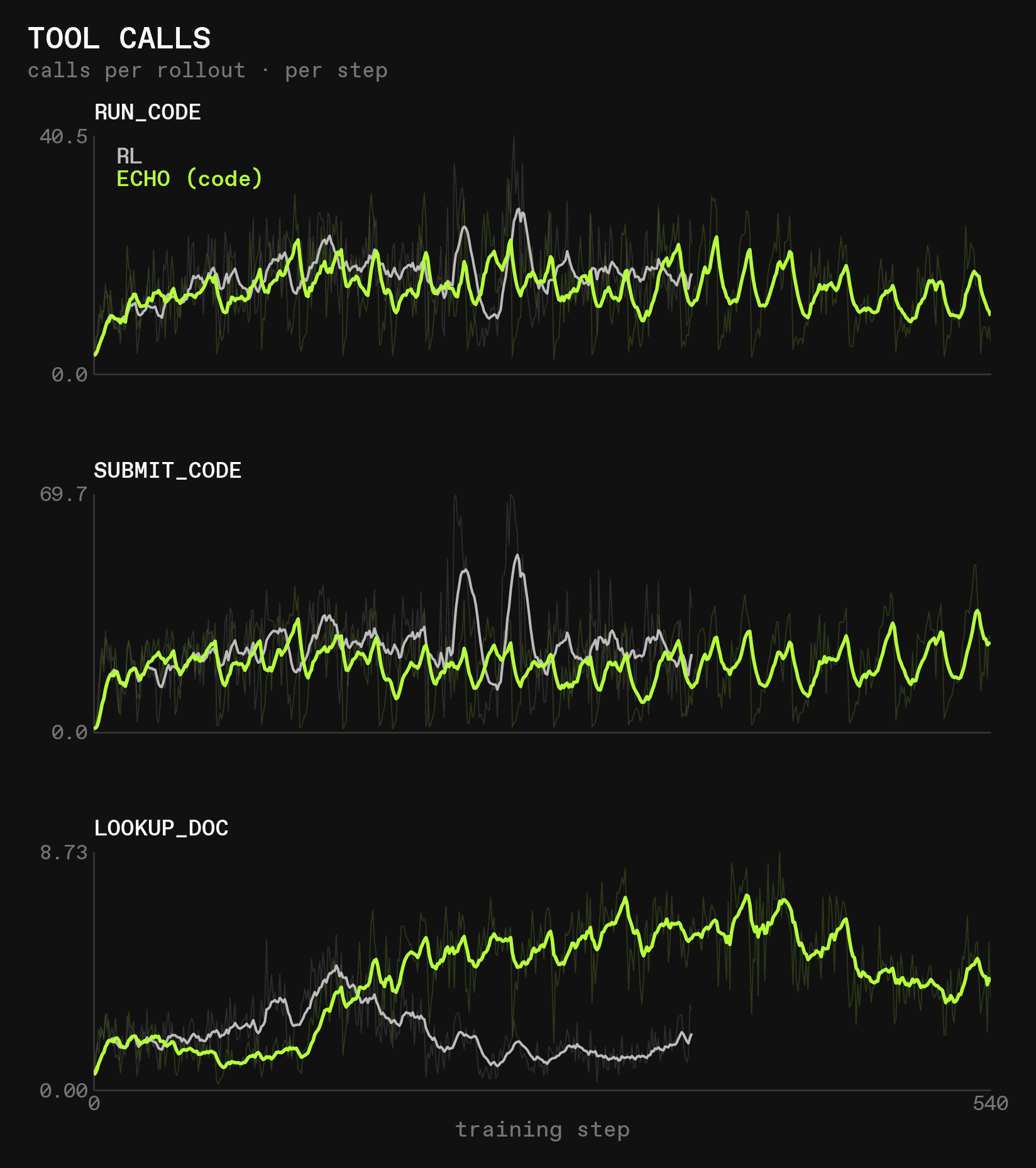
Both modes call mostly the code tools, in roughly equal quantity. However, lookup_doc shows strong differences between the two: both learn to use it more often at first, and then less often again (though RL shows a small upward tick again toward the end). But the peak of lookup_doc usage comes later and is higher for ECHO (code) than for RL, and its usage falls more slowly. We will speculate more on this later.
The token usage also differs strongly (note the difference ranges on the x-axis between the two):
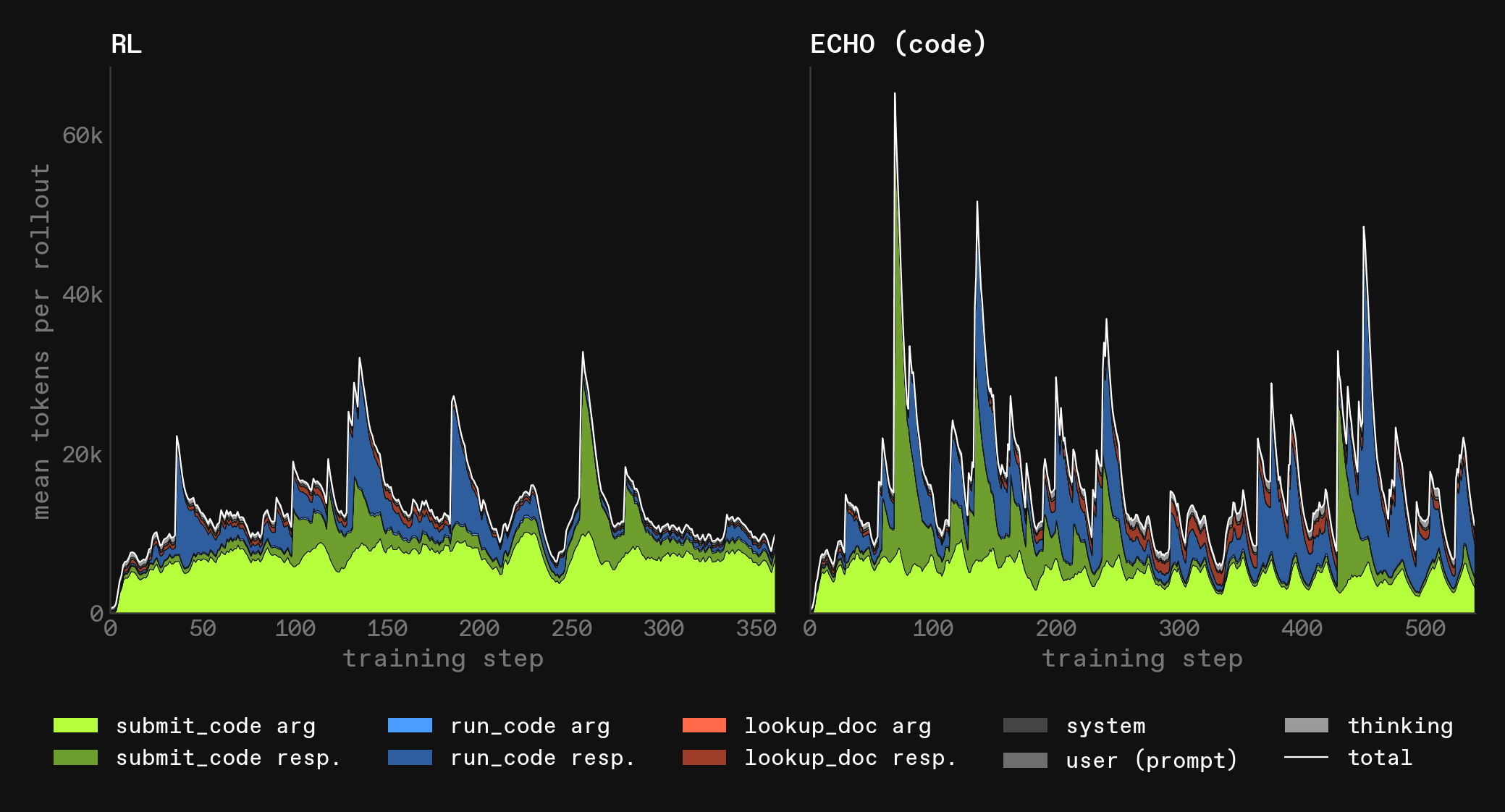
ECHO (code) tends to produce fewer model tokens but gets longer responses. Almost all model tokens are tool tokens; but since it uses the same number of code tools and makes more calls to lookup_doc, this is clearly not a result of doing fewer tool calls in general. Instead, the tool calls that are being made use shorter inputs and produce longer outputs.
We draw three conclusions from these experiments:
- GLM-4.5-Air is highly sensitive to the value of
alpha - ECHO works very well, improving performance in domain at increased efficiency without degrading performance on other domains
- Overfitting is likely a greater concern with ECHO than with pure RL, though this is uncertain
forth-lang: Qwen3-4B-Instruct-2507
We performed a number of ablations with Qwen3-4B-Instruct-2507 while the environment was in active development, and before our experiments on GLM-4.5-Air. They were all run with Muon.
500 steps
We decided to test two values of alpha: {0.05, 1.0}. This provides wide coverage of the hyperparameter over a full run with online evals. We used 500 steps, a total batch size 256, and a group size of 16.
Note: for the
alpha=1.0run that trains on all tool outputs, a few datapoints are missing, but the overall trends are still clearly visible.
Reward
The reward is very similar between all runs:
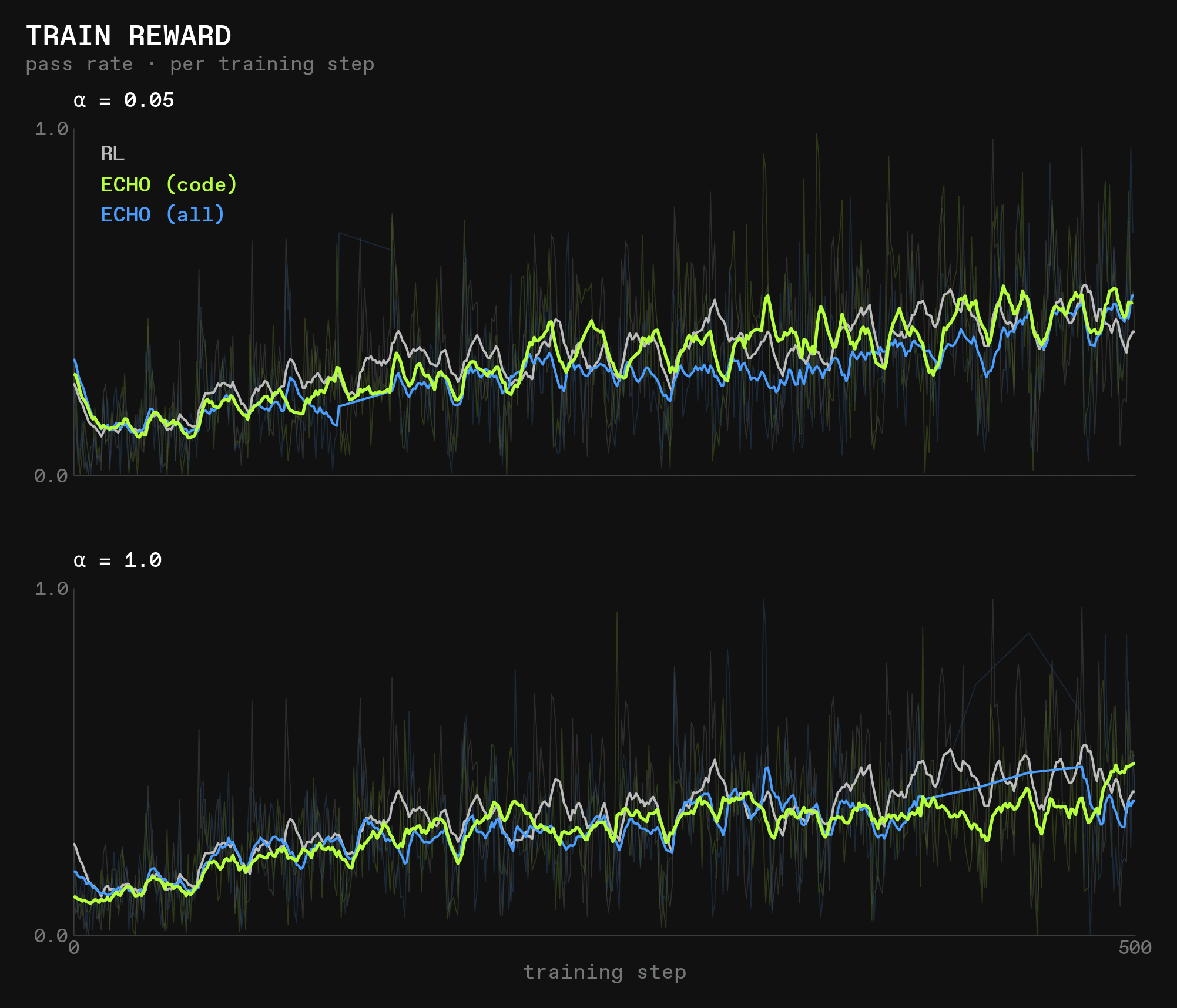
At least at this step count, any differences in reward are small and cannot be distinguished from random noise. Neither the tool choice nor the value of alpha seems to make a difference.
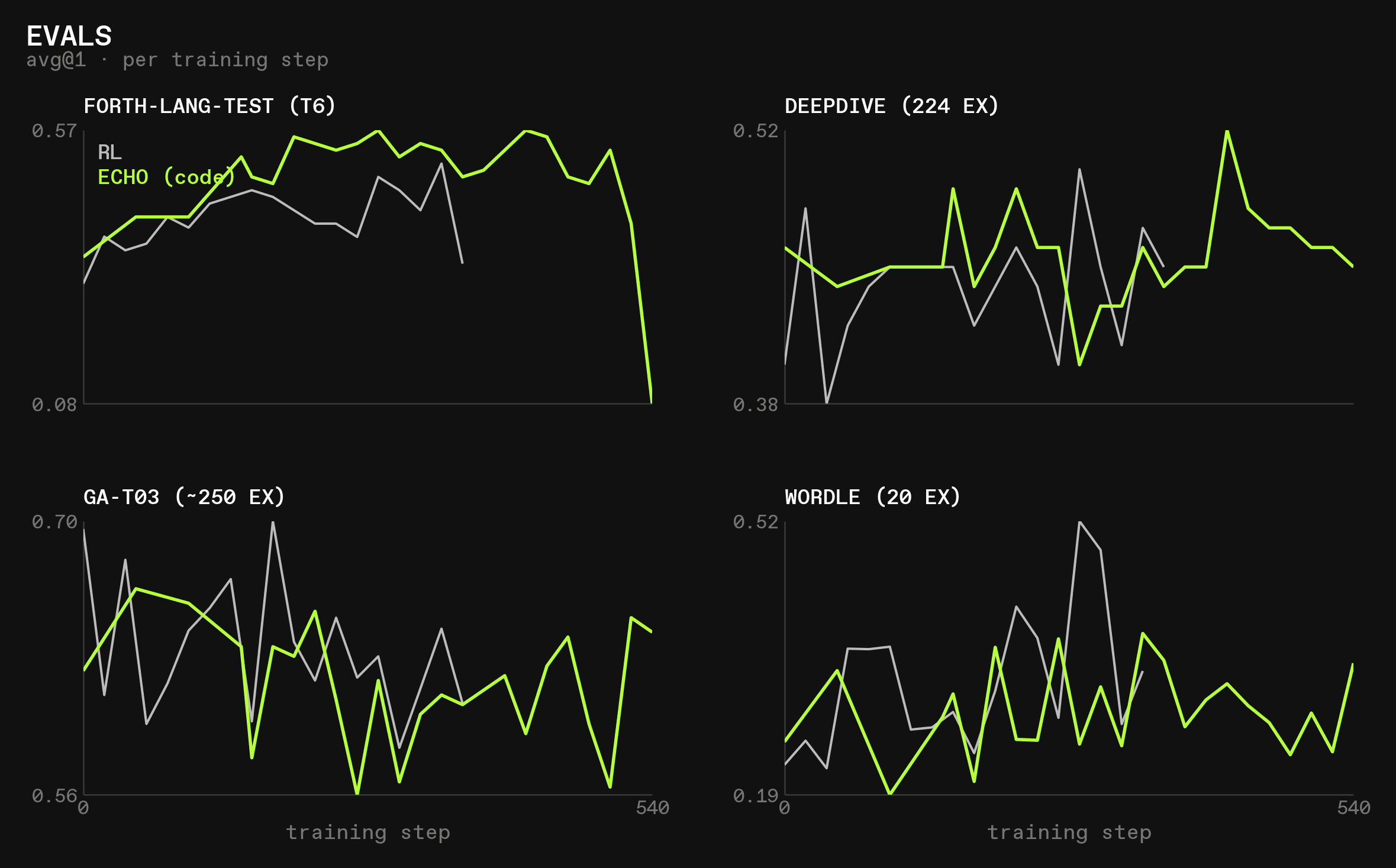
Evals
Evals give a much more significant signal:
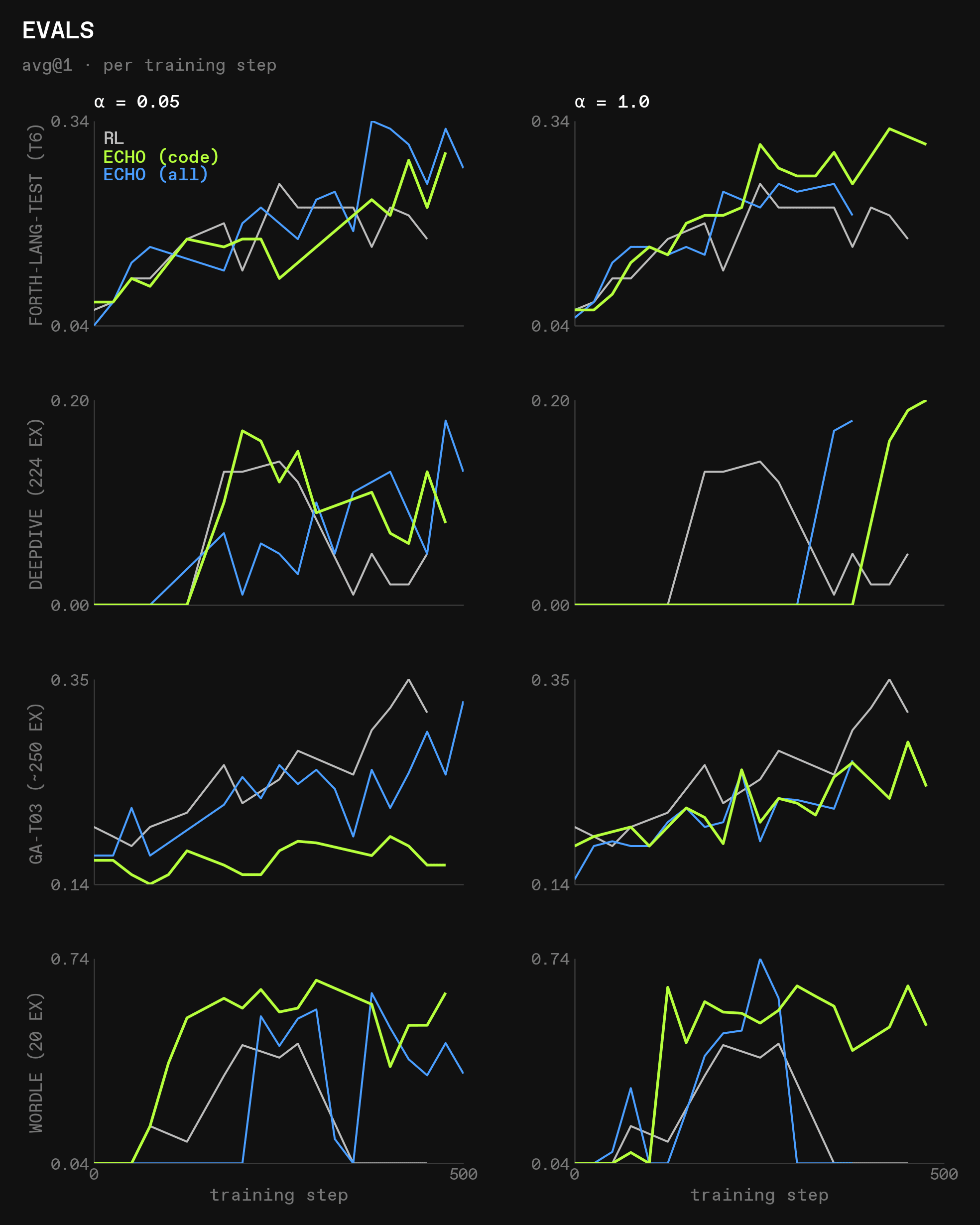
A few observations:
forth-lang-test: world modeling clearly and consistently helps generalization in the training domain. This strongly suggests that in order to learn a specific, previously poorly known domain, world modeling is helpful. It is especially notable that in these runs, theforth-langtraining set consisted of difficulty levels 0-5, while the test set was level 6, showing strong generalizationdeepdive: surprisingly, and counter to our hypothesis, the runs performing world modeling generalized better todeepdivethan pure RL did. As we will see later, this is purely a function of how much each training modality teaches the model to uselookup_doc, but it is still remarkablegeneral-agent: world modeling onforth-langreduces generalization togeneral-agentcompared to pure RL. This tracks with our hypothesis: it is a retrieval-style environment, but requires more complex tool usage thandeepdive, so learning to spamlookup_docand similar tools doesn’t workwordle: this logic environment benefits greatly from world modeling on forth-lang- In general, ECHO seems to interfere with out-of-domain evals more strongly for the small Qwen model than for the large GLM model, which is a good sign for the scalability of the method
Tool use
As stated before, some of the eval results can be explained by the tool use patterns learned by the different runs.
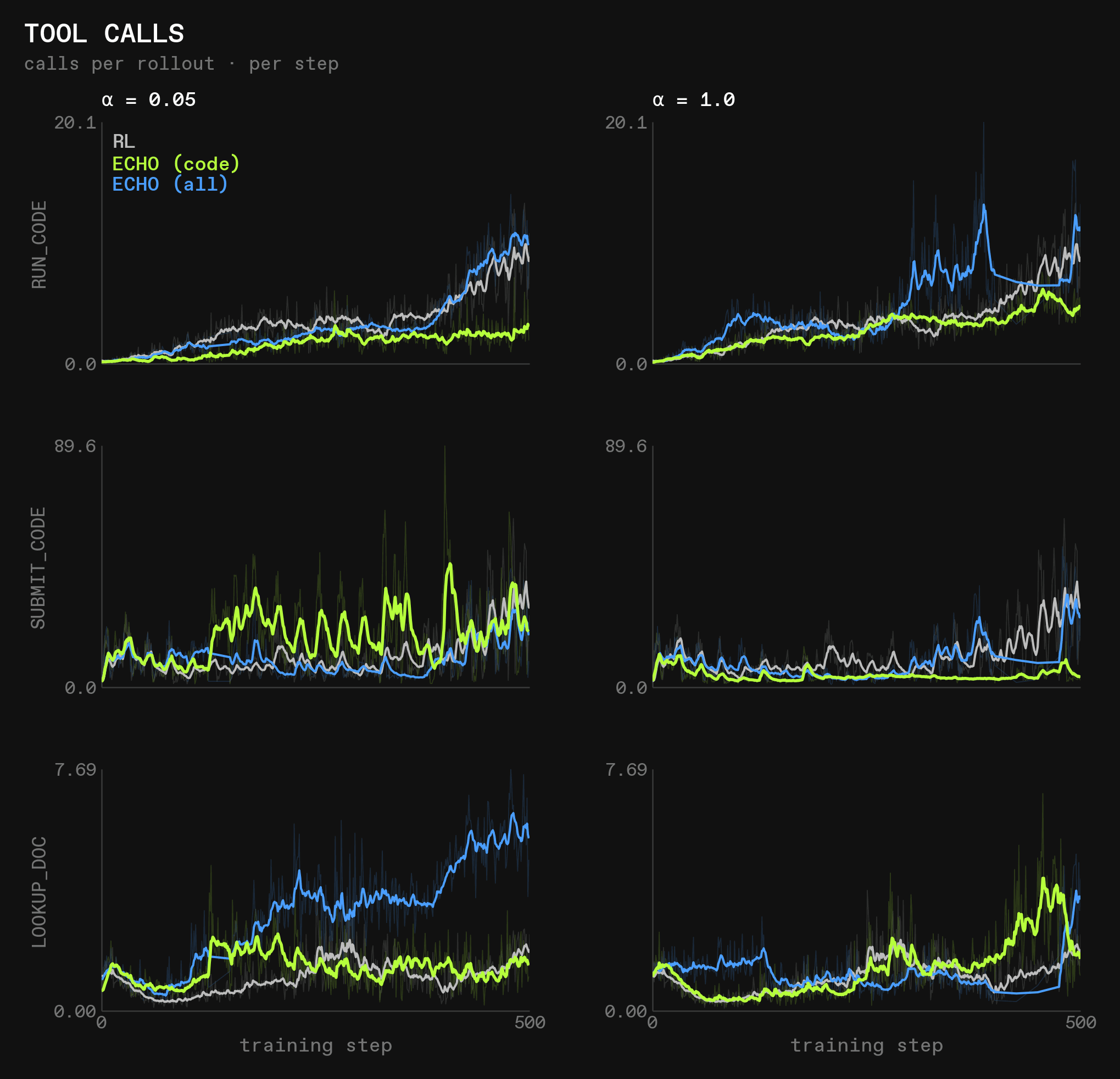
What stands out immediately is that world modeling again causes an increase in the usage of the lookup_doc tool, like with GLM-4.5-Air. This explains the over-performance in deepdive, which can mostly be solved by spamming the search_web tool, but it is surprising because becoming better at predicting the outputs of lookup_doc should reduce the utility of the tool.
We are not certain what causes this, but have a hypothesis. It assumes that predicting the code, and even more so the documentation itself, helps models internalize how the language works. This seems evident from the gap between training and eval scores, where world modeling seems to mainly help with generalization.
The hypothesis is that this helps the model make more use of the documentation: since it can predict its contents more accurately where it already knows the language, the surprisal in the parts of forth it doesn’t yet know is significantly more pronounced in comparison, giving the model a strong signal for ICL and self-correction. This increases the utility of lookup_doc, and that makes the RL signal increase its usage over time.
The flip side of this theory is that after some time, the model should know all parts of the documentation that are useful to it, which then significantly reduces the usefulness of lookup_doc and leads to a reduction in its usage. Indeed, we can see that happen in ECHO (code) at alpha=1.0.
Note: Another interesting aspect of this theory is that most of the gains in understanding seem to come from predicting the outputs of compiling and running programs, and learning the documentation actively only slightly adds to this, which tracks with our hypothesis that predictability without memorization and complexity are both important prerequisites for world modeling. This is evidenced by ECHO (code) showing very similar behavior as ECHO (all).
To gather more evidence either way, we will move on to experiments that ran for 1000 steps next.
1000 steps
This set of experiments on the same model ran for 1000 steps but half the batch size, which was 128. The group size was reduced to 8, which means that we still used the same number of prompts per step as in the experiments presented above. We always use zero-advantage filtering, which means that every batch we use has some advantage signal for RL, important with such a small group size.
In these experiments, alpha was fixed to 0.5. We instead varied the constraint on the maximum number of turns: once to 200, which is the default we use in the other experiments as well, and once to 10.
The intention was to find out if ECHO helps more in constrained settings than in unconstrained ones. This was inspired by very early ablations showing ECHO runs typically using fewer turns to achieve the same or better results compared to pure RL.
Reward
We start again with the reward:
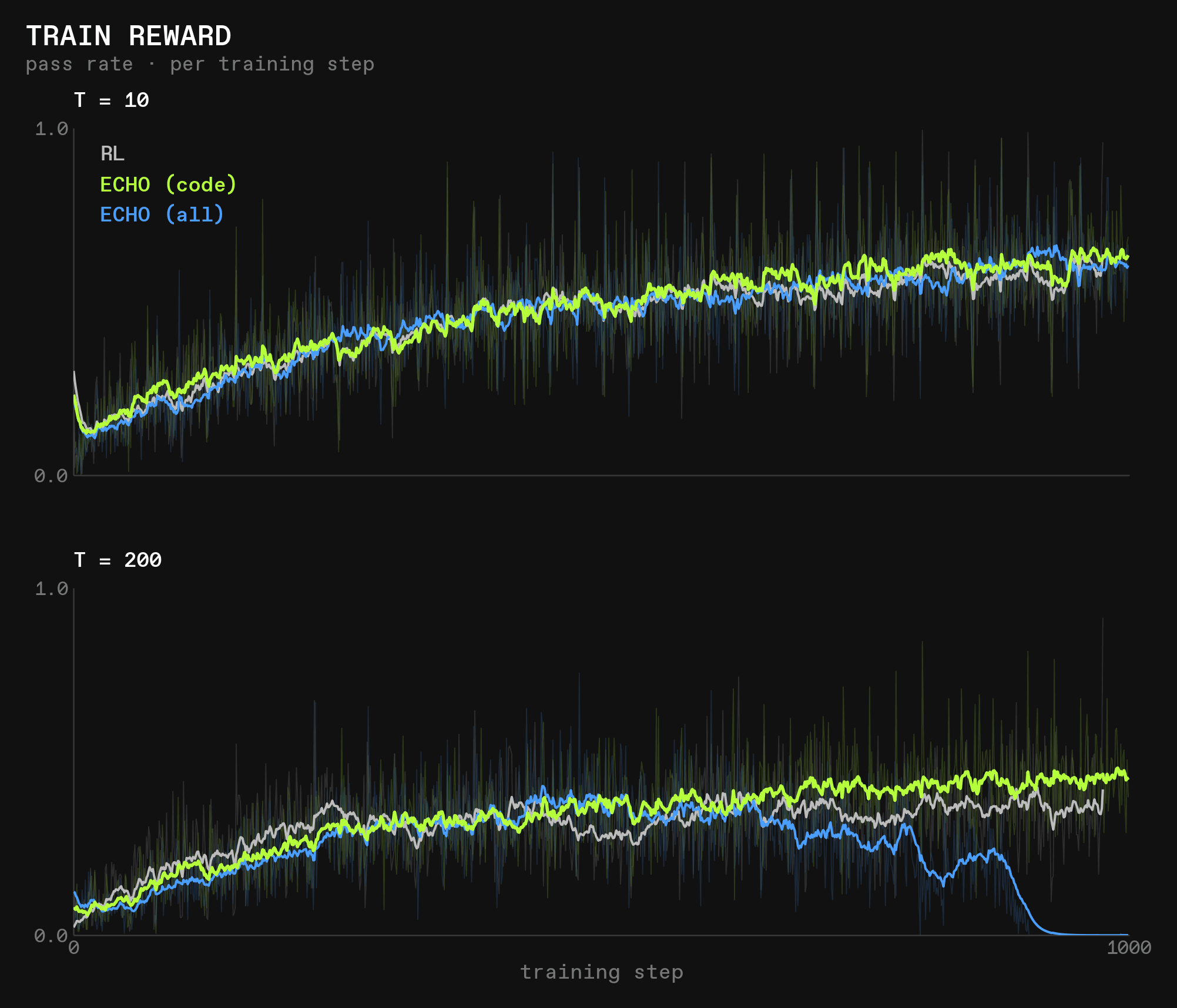
What’s immediately clear is that limiting the number of turns improves model performance for Qwen3-4B-Instruct-2507.
We can also see that with enough turns, ECHO (all) collapses after about 600 steps, though the first 500 steps are looking very strong. Finally, in the 200-step setting, ECHO (code) is the strongest, but in the 10 turn setting, no real differences can be seen between any of the three settings for the entire 1000 steps.
Evals
The evals are again more interesting:
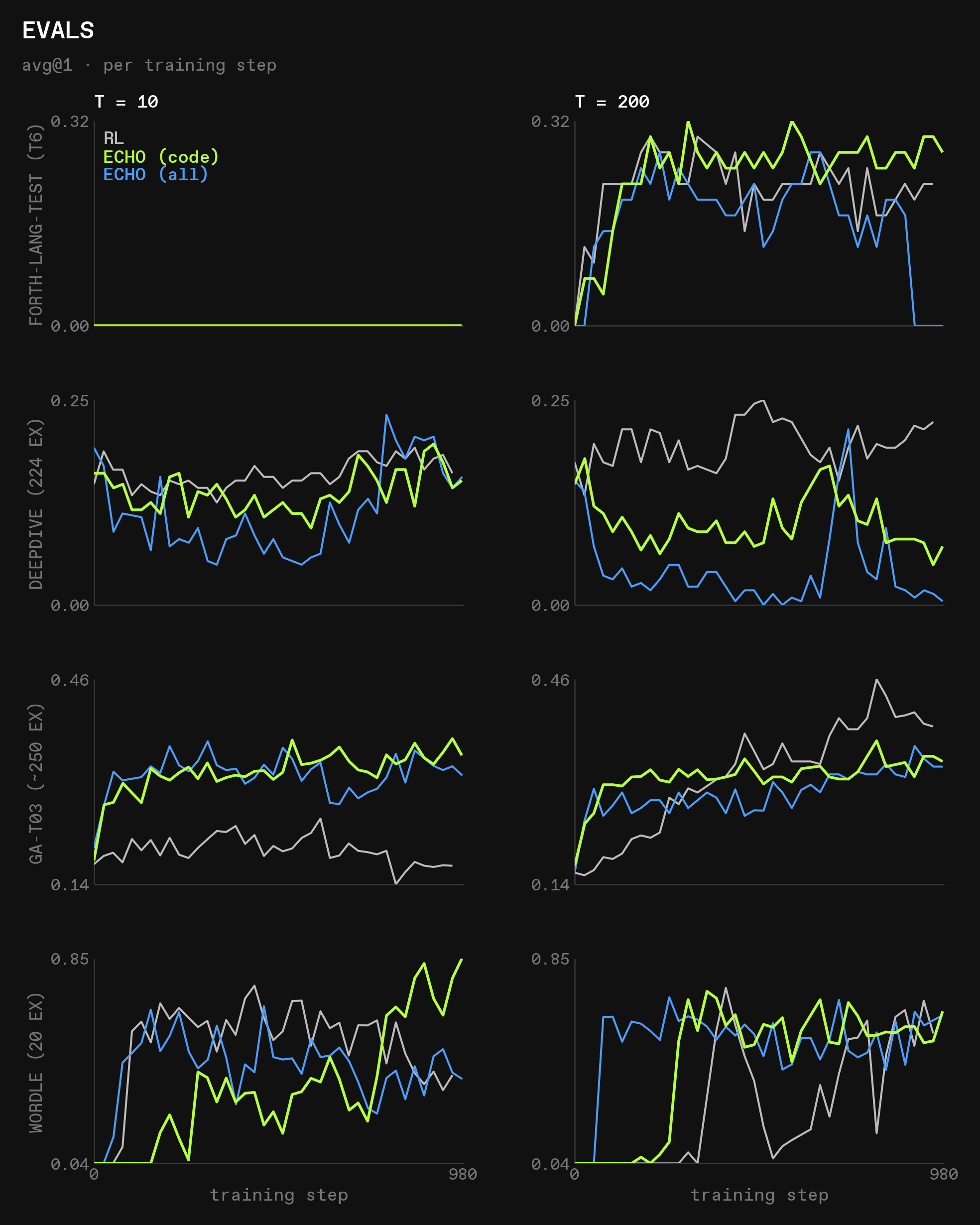
forth-lang: inforth-langitself, the models constrained to 10 turns don’t generalize at all to harder test problems, despite them having a higher training reward. With 200 turns available, world modeling again helps improve generalization onforth-lang, except where the run collapses. Importantly, we see no signs of overfitting in ECHO (code) within 1000 steps, which at 16 prompts per steps means more than 38 epochs seendeepdive: world modeling hurts performance compared to pure RL. This can again be explained by how much thelookup_doctool is used, as we’ll show below. However, in the 10 step setting, both ECHO runs eventually catch up to pure RLgeneral-agent: in the constrained setting, world modeling onforth-langgeneralizes significantly better togeneral-agentthan pure RL; in the 200-step setting, they generalize worse. Interestingly, while performance on forth-lang crashes for ECHO (all) with 200 turns, it stays good ingeneral-agent(andwordle), a pattern also seen in GLM-4.5-Air beforewordle: world modeling onforth-langconsistently improves performance onwordle
Tool use
The tool usage displays interesting patterns:
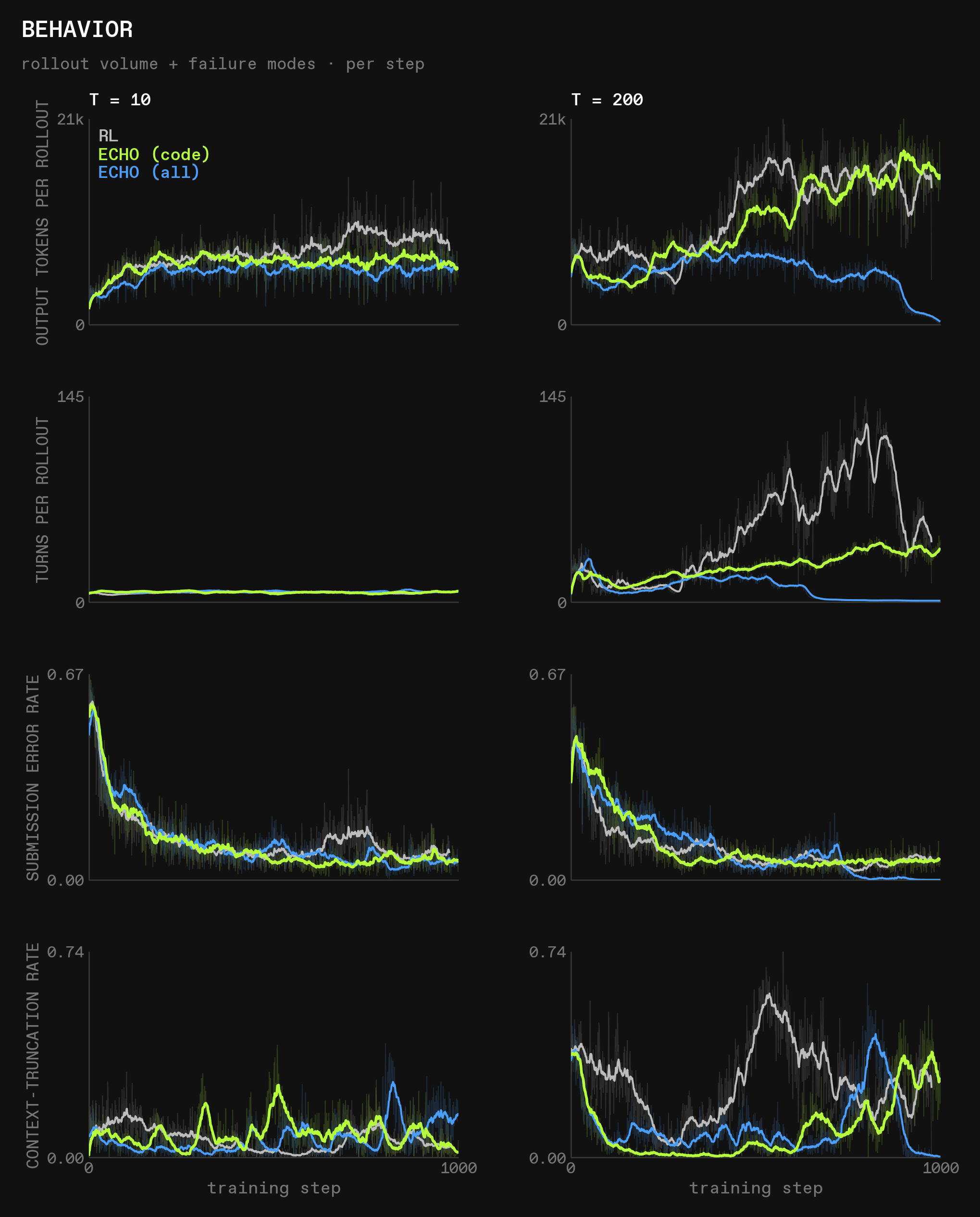
- A lot of behavior only settle after >500 steps: all tool use patterns from pure RL in the 200 turn setting, for example, or the collapse of tool use of ECHO (all)
- Pure RL uses more tools in general, at least in the 200 turn setting; in the 10 turn setting, all three make the same number of tool calls, just in different ratios between the tools
- In the 200 turn setting, the frequency of
submit_codeandlookup_docis inversely correlated, likely because the documentation helps the model avoid submissions that throw errors - Like before, world modeling causes an initial spike in
lookup_docusage, but in this version offorth-langand with thisalpha, the collapse to very few lookups happens early in training; the peak is after little more than 50 steps. We take this as evidence in favor of the theory that world modeling helps models make better use of documentation up to the point where they have internalized the environment dynamics sufficiently, at which point they no longer need it. This is corroborated by the far higher usage oflookup_docdeveloped by RL
deepdive
The experiments on deepdive were run in parallel to the 500 step Qwen3-4B-Instruct-2507 experiments on forth-lang. They also used a total batch size of 256 (16 prompts x 16 rollouts per prompt), went for 500 steps, and were run at alpha=0.05 and alpha=1.0. Again, some samples were lost, but again, the trends remain clear.
In deepdive we always train on all tools.
Reward
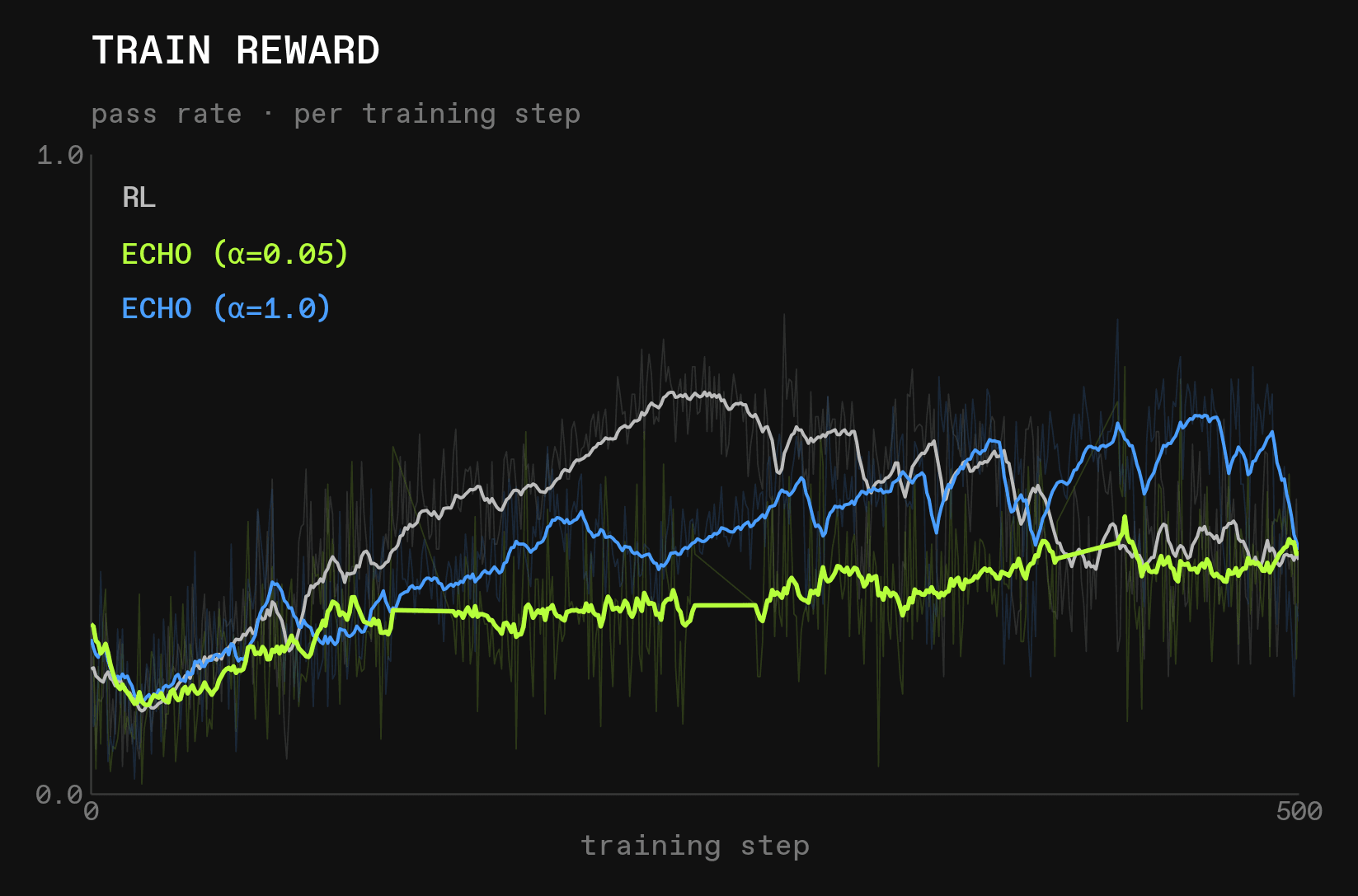
- RL learns more quickly than world modeling, and reaches a higher reward-peak, but begins to regress after ~250 steps
- ECHO leads to a more consistent improvement in reward, which seems to not have plateaued in the first 500 steps, which helps it catch up to RL after that time
Evals
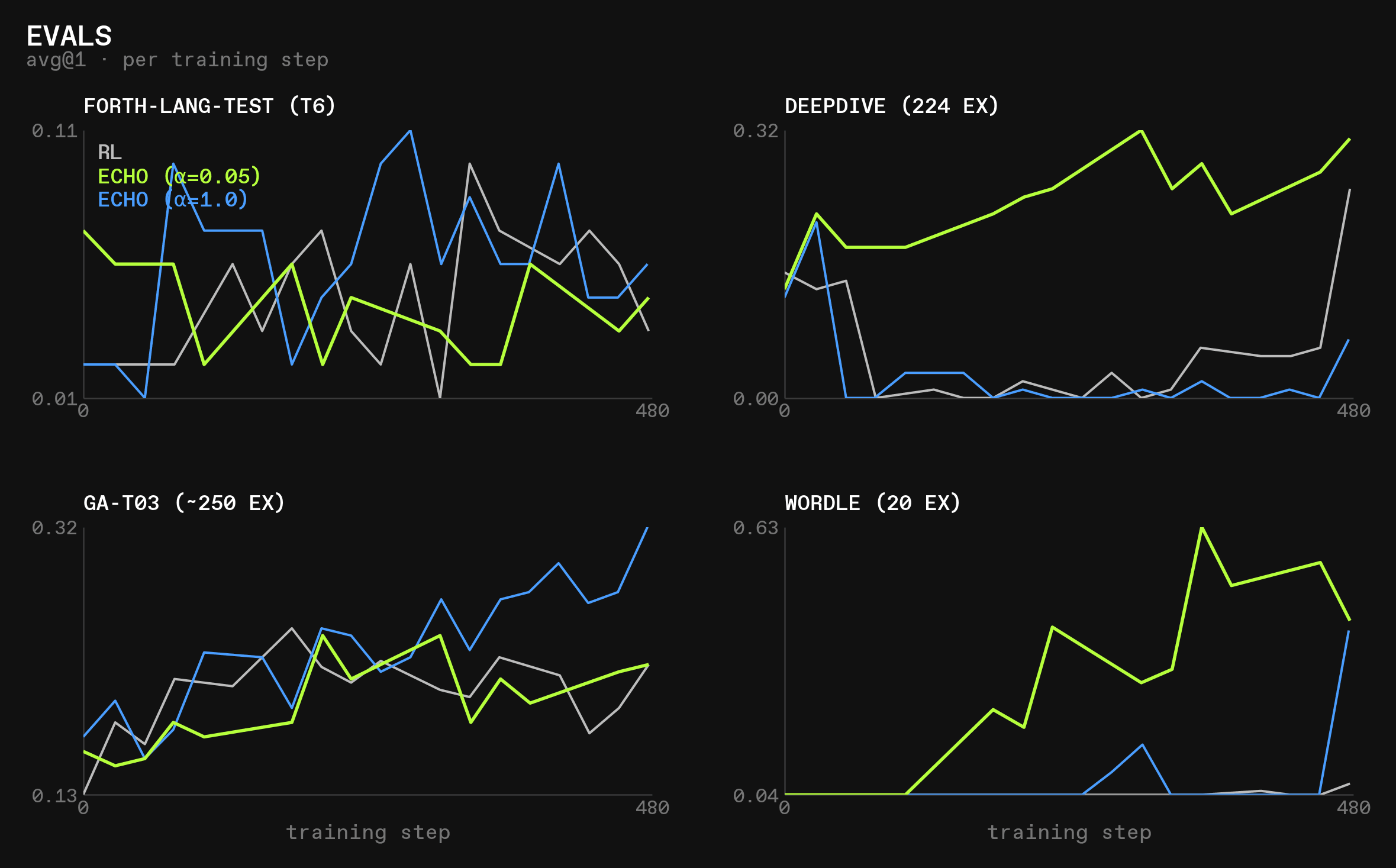
Overall, the eval results seem to contradict our theory of simple, pure retrieval environments being a poor fit for world modeling:
- With a low
alpha, world modeling significantly improves generalization to thedeepdivetest set - And generalization to other environments is either better (
wordle) or at least not significantly worse (general-agent,forth-lang) than pure RL
However, we happen to have run the alpha=0.05 experiment for almost 700 steps, and it shows clear signs of overfitting shortly before finishing 600 steps, or about one full epoch (2.23k samples in the dataset at 16 samples per step means roughly 560 steps for one epoch).
The reward starts going up more quickly than before:
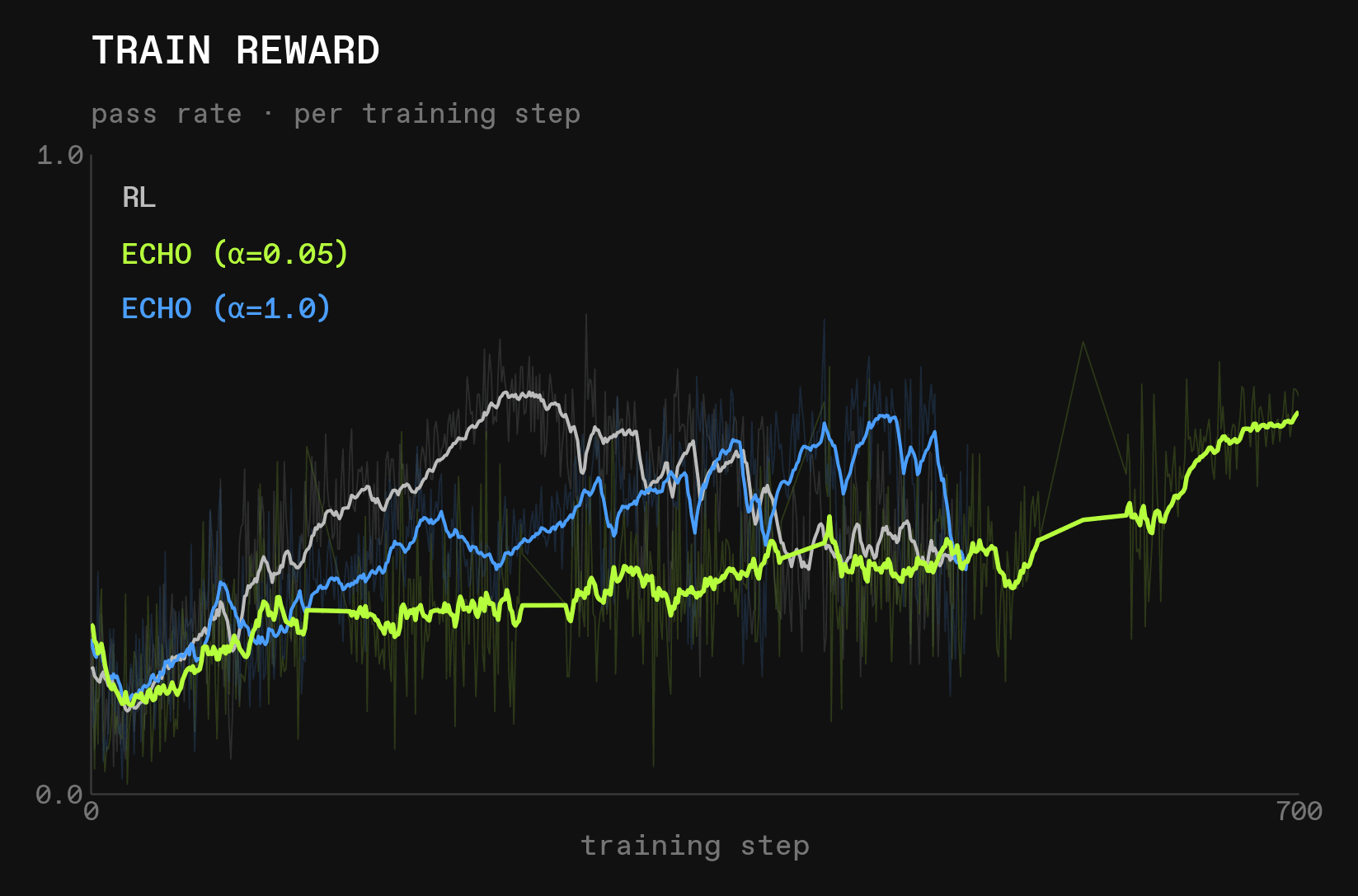
But at the same time, the deepdive (and wordle) evals crash:
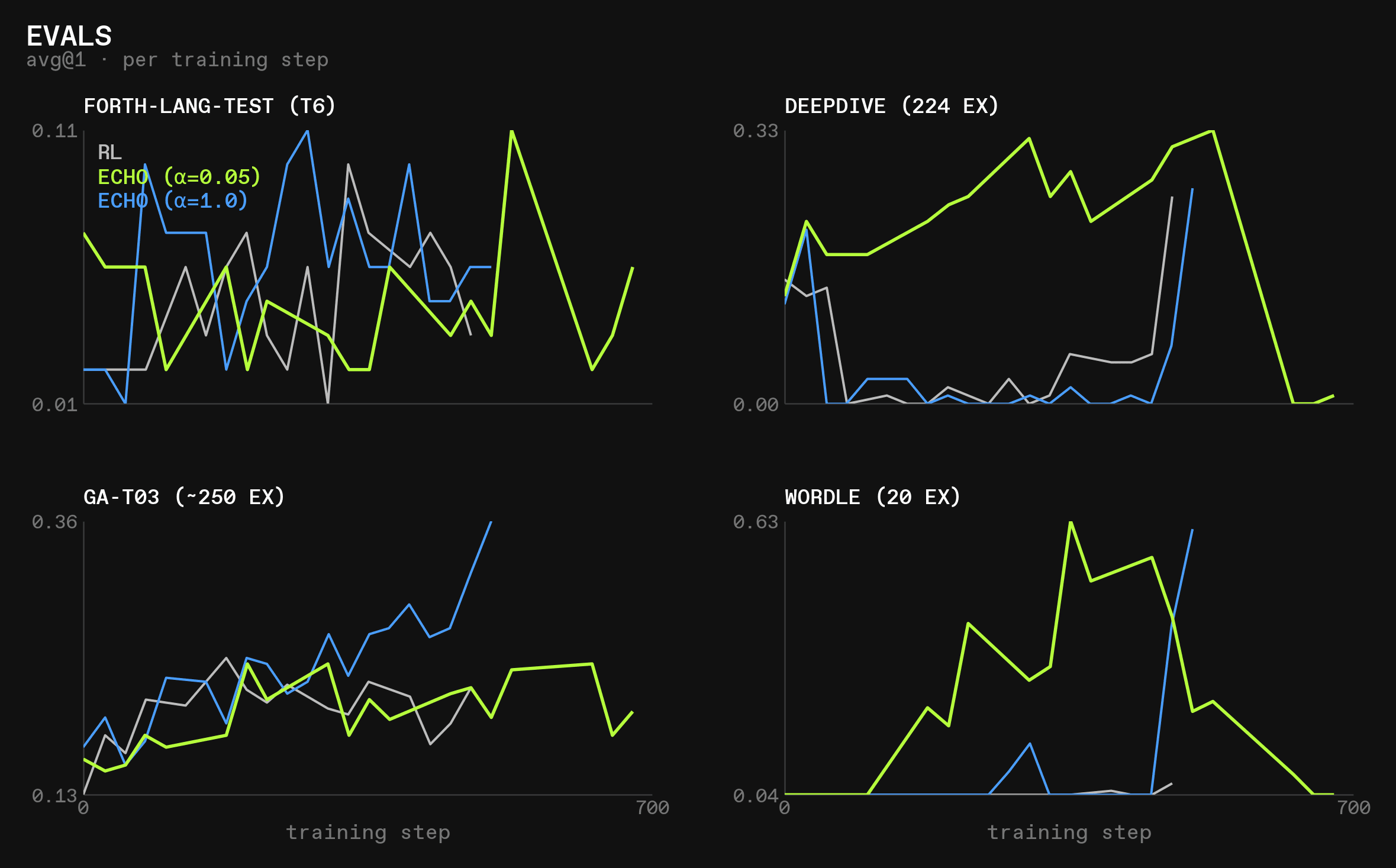
This suggests to us a different mechanism to us than what we initially theorized:
The persona selection model suggests that most skills, knowledge, and behaviors are learned during pretraining and only expressed and composed during posttraining. This means that if posttraining negatively impacts performance on some tasks but more than makes up for it by improving it on others, then getting some of that lost pretraining task performance back without degrading posttraining task scores will improve overall intelligence.
And in very early experiments, we did find that world modeling in this manner lowers perplexity on wikipedia text significantly (more on this later).
The point is that web search results are far more predictable and at the same time complex than we assumed. This should have been obvious in hindsight because it’s very close to pretraining, and that is clearly a complex but predictable task.
Overfitting in forth-lang came late or never, but in deepdive it comes after one epoch. This brings us to a new conclusion: tools whose outputs can be memorized are useful in single epoch training if their outputs are non-trivial, but will lead to heavy overfitting in a multi-epoch setting, as is typical in RL. Tools for which generalization is a more efficient strategy can be trained on for many epochs.
Tool use
Tool use statistics explain the over performance of the ECHO run with alpha=0.05:
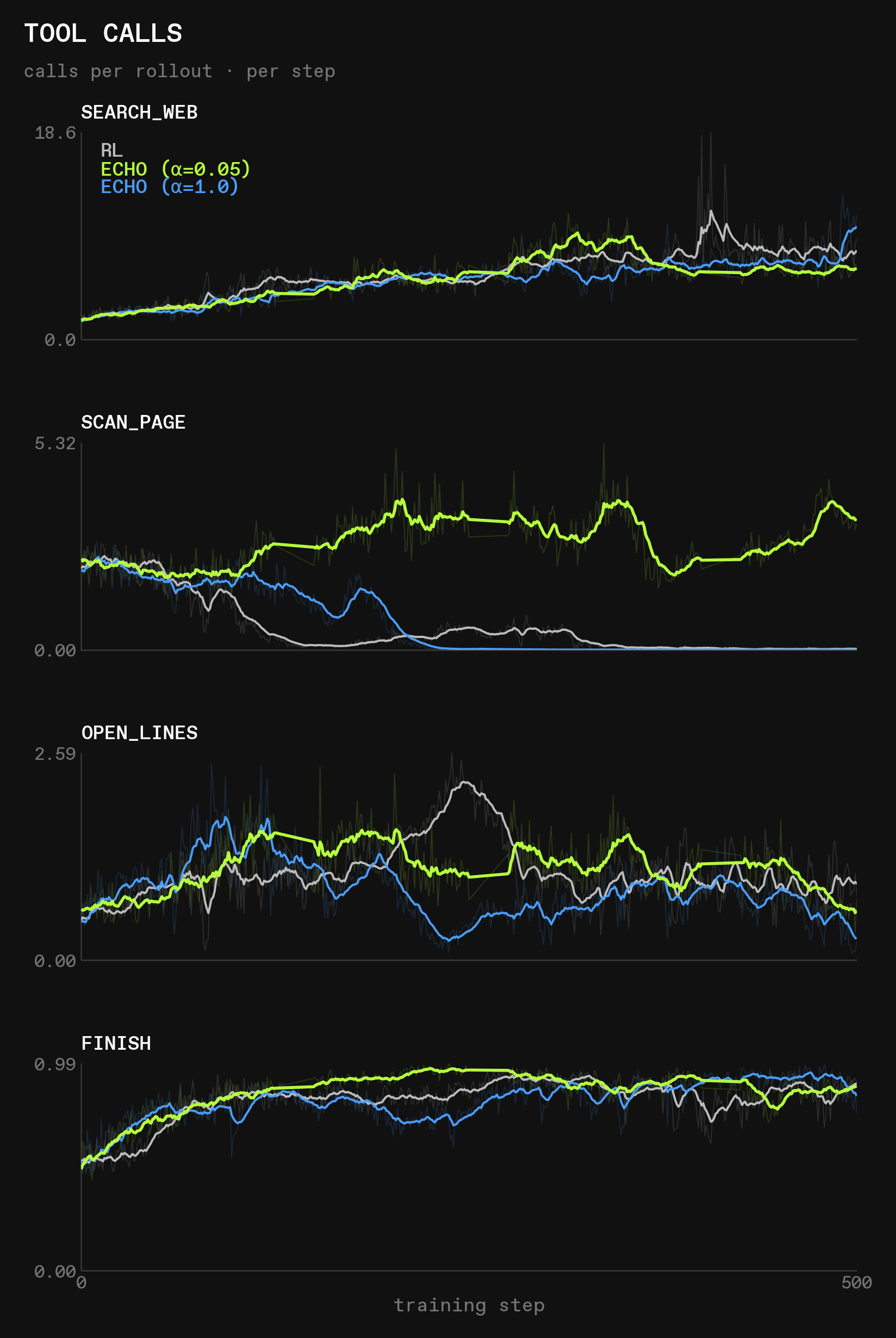
- All runs cause the model to search the web more, and
search_webis by far the most used tool - But only the most successful run uses
scan_pageto a significant degree; it’s the only one actually searching within webpages, as the second most used tool (the other two completely stop using it) - This suggests that there is some randomness in play regarding the rewards and eval results; though
alpha=1.0also leads to fairly good results, so randomness is unlikely to be the only factor
Perplexity analysis
We initially ran small tests by training on deepdive, general-agent, wordle, and combinations of the above, and measured the perplexity on wikipedia (config "20231101.en", split "train"). This is on only 200 documents, with ≤256 tokens each, but the trend is glaringly obvious.
In the plot below, the training environment is written on the left. SFT-only means ECHO-style SFT on tool outputs of real rollout, with the RL loss zeroed out. multi-env means the model was trained on general-agent and wordle in equal proportion.
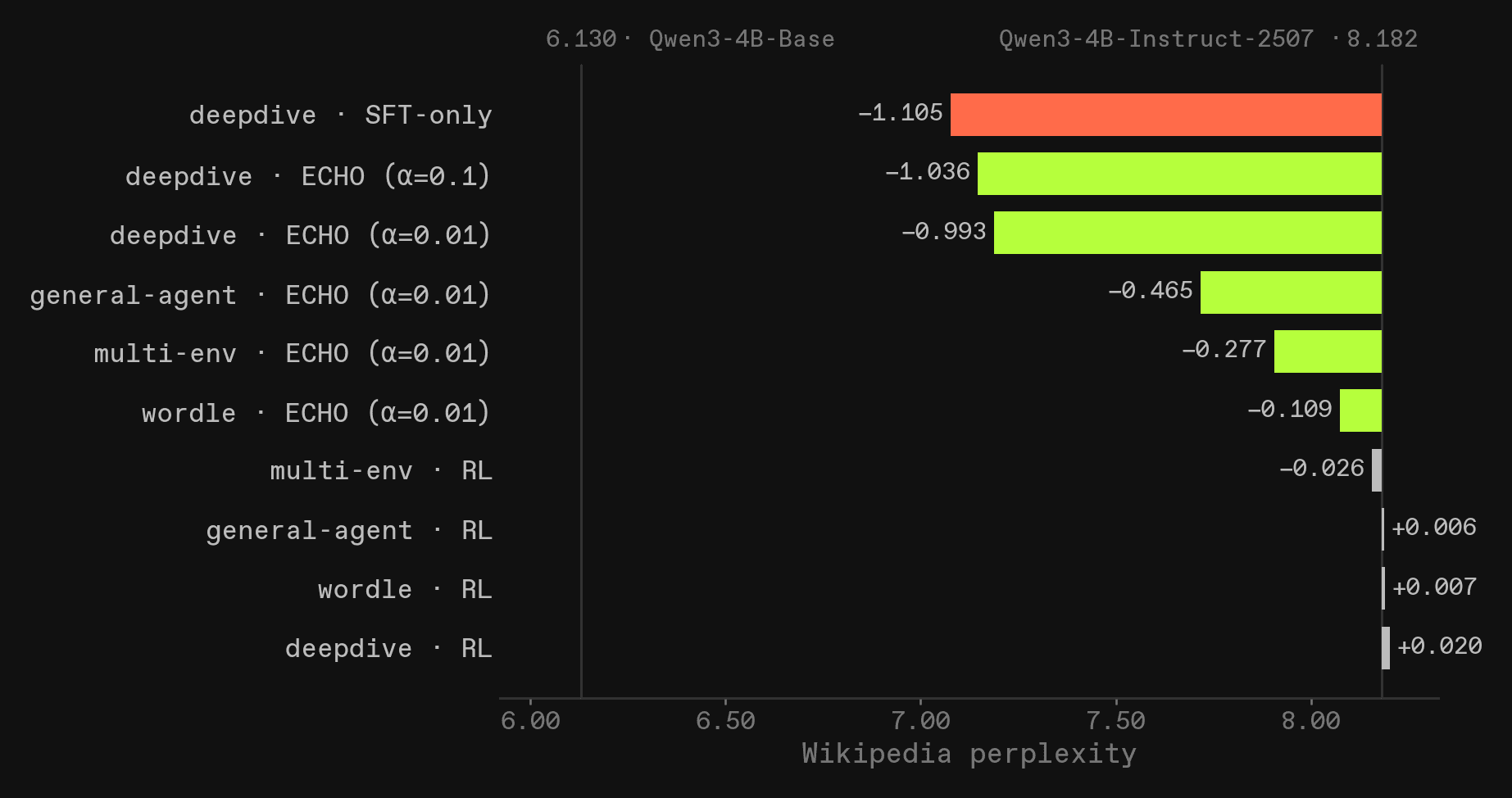
It is very clear that world modeling on any environment expresses the pretrained simulator in LLMs. It is also clear that deepdive does this by far the strongest, which should be unsurprising given that it’s a pure web-search environment while the others are more posttraining style. Pure SFT leads to the largest perplexity reduction, but not by much. RL on top of the already post-trained Qwen3-4B-Instruct-2507 barely moves wikipedia perplexity.
The other results from the very short, early experiments were inconclusive, except that pure world modeling without an RL loss clearly degrades task performance. This might be due to a lack of model capacity from a 4B model, and it might work better in different environments, but we suggest never setting the RL loss to zero.
What we learned
Let’s go over our initial hypotheses and discuss what we learned about them.
-
World modeling during RL will make learning faster and more efficient.
Verdict: True. With almost no additional costs, and generally reduced number of tokens, it leads to better in-domain generalization without consistently hurting out-of-domain generalization. This is more pronounced in the fairly large GLM-4.5-Air (110B parameters) than in Qwen3-4B-Instruct-2507 (4B parameters), which is a good sign for the scalability of ECHO.
-
This will be especially true on domains not encountered much during pre- and mid-training.
Verdict: Unclear. The model learned well on
forth-lang, which it likely didn’t encounter much before. But it also learned well ondeepdive, which is very similar to data it has previously seen. Yes, after a while generalization collapsed, but that was due to the memorization-heavy nature of the environment leading to overfitting, not due to the lack of environment-novelty. -
World modeling works best under two conditions:
- The tool outputs are predictable without memorization, because that both shows and drives generalization
- The tool response is complex, so that training to predict the tool response makes a difference that isn’t trivial
Verdict: Most likely true. However, there are additional interactions between tools that make it harder to apply this rule to any one environment, and more tasks are difficult to predict than one would think. It is clear though that tasks that can only be solved through memorization suffer from overfitting far more quickly than algorithmic tasks.
-
SFT on purely knowledge-based tool outputs, like a search through documentation, makes the model internalize the knowledge more deeply than directly training on the documentation.
- The Cartridges paper showed that in order to internalize a piece of knowledge, it is better to re-formulate it into a Q&A dataset and training on that than to train directly on the document
- We hypothesize that training on the output of search through documentation during a real rollout has a similar effect: Cartridges presents the same information in the context of different questions, world modeling on documentation presents the same information in the context of different tasks and call to specific code
Verdict: Unclear. Generalization in-domain was strong for
deepdive, which could be due to simply re-activating latent world modeling capabilities, or due to the data being presented in an agentic context.As for
forth-lang, compared to training only on code tools in, training onlookup_docmade the model better at predictinglookup_docand not clearly worse otherwise. It did increase the usage of the tool early in training more than ECHO (code) did, and crashed it more thoroughly, but the reasons for this are unclear.We hypothesize that this pattern comes from wrong predictions of
lookup_docgaining high utility when the model is better at making predictions for most calls of the tool, as it provides a strong correction signal. We also hypothesize that the following crash inlookup_docusage is caused by the lack of such wrong predictions after a while, and RL preferring rollouts that don’t uselookup_docfrom that point on because it wastes tokens without bringing utility. However, we don’t see this hypothesis as fully supported yet, and present it only to enable future work.
One additional outcome of our experiments is the importance of overfitting. In deepdive this occurs after approximately one full epoch, in forth-lang after 10 in the GLM runs and not even within 38 epochs in the Qwen runs. This suggests to us that for tool outputs that are heavy on data and light on algorithmic structure, overfitting is a significant concern with ECHO, but for complex but predictable tools, it’s a far lesser issue.
It’s possible that it would be better to train with ECHO for the first few hundred steps, then with pure RL. It’s also possible that only training on tokens tool outputs with a minimum loss value would prevent overfitting by avoiding re-training on already-known tool-calls, or that other techniques would help. For now, we recommend applying ECHO carefully and on a case by case basis.
Final words
ECHO is a promising technique that seems to work at scale. We believe that it will soon become an important part of open model training, especially where data is abundant and overfitting isn’t a risk. It opens the door to many directions of research. Therefore, we will soon support it in a highly flexible and performant manner in prime-rl.