Leveraging NVIDIA to Build the Open Superintelligence Stack

Leveraging NVIDIA to Build the Open Superintelligence Stack
The next frontier of AI infrastructure is building systems for models that can run autonomously for hours, use tools, execute code in sandboxes, and learn from outcomes at scale. At Prime Intellect, our platform spans agentic RL training on frontier open-source models, agentic inference across global deployments, sandboxed environments optimized for reinforcement learning, and the open-source libraries verifiers and prime-rl that tie everything together. Through research like INTELLECT-3 and thousands of hosted training runs, Prime Intellect's goal is to democratize access to a state-of-the-art agentic RL stack that was previously accessible only to the largest labs.
Today, we're sharing how our collaboration with NVIDIA enables our open superintelligence stack. Our training and serving workloads run on NVIDIA Blackwell — and soon, NVIDIA Vera Rubin — systems at rack scale. NVIDIA Dynamo powers our global-scale inference orchestration with efficient routing, autoscaling, and KV offloading. We've also been optimizing our sandbox infrastructure to work well with next-gen NVIDIA Vera CPUs, enabling both low-latency and energy-efficient RL. NVIDIA's open-source contributions like NVIDIA Nemotron models and NVIDIA NeMo Gym environments are also integrated into our open stack, accelerating the democratization of intelligence.
Using Next-Generation NVIDIA Clusters in Lab
At Prime Intellect, the Lab is our product for turning ideas into better models. Built for agentic post-training, Lab brings together our infrastructure for environments, training, and evaluation, making it easy for anyone to move quickly from research to production.
To power Lab, we've been collaborating with NVIDIA to leverage the latest advancements across their hardware and software stack. At the hardware layer, NVIDIA Blackwell and Blackwell Ultra clusters and rack-scale NVIDIA NVL72 systems have enabled us to train and deploy models with much higher efficiency compared to our previous Hopper clusters. We've begun to co-design our systems around features like the NVIDIA CMX context memory storage platform, powered by NVIDIA BlueField-4 processors, for efficient KV offloading and Vera CPU racks for efficient CPU acceleration and sandboxing. We're also adopting NVIDIA Vera Rubin NVL72 systems for the next generation of agentic models.
Inference with NVIDIA Dynamo
Inference is becoming extremely important for both RL rollouts and agentic model deployment into production. Globally distributed inference, long-context reasoning, multi-turn agent loops, models with sparse expert architectures, and serving large fleets of specialized adapters are challenges we've run into that require robust infrastructure. We evaluated multiple candidates and then chose NVIDIA Dynamo as our inference layer due to its rich feature set, strong performance, and production maturity.
NVIDIA Dynamo is used across our deployments, from large-scale LoRA serving with Lab to large-scale MoE inference such as the Arcee Trinity model on OpenRouter. We leverage features like fast autoscaling with Model Express, P/D disaggregation, Grove for topology-aware placement, global planner for autoscaling across multiple context pools, and KVBM for KV offloading. We worked with NVIDIA on enabling LoRA adapter deployments, allowing optimal placement and routing of LoRA adapters across multiple engine instances.
Our collaboration also extends into reinforcement learning libraries and tooling. We are integrating Dynamo into our prime-rl open-source library. Supporting agentic inference at scale requires robust orchestration, efficient routing, elastic scaling, and fast adapter-aware serving, and we are excited to use NVIDIA Dynamo as the backbone of our inference clusters.
Sandboxes on NVIDIA Vera CPUs
Sandboxes are the infrastructure backbone underpinning RL environments. They execute agentic actions, from code execution to web browser interaction, in fully isolated, disposable environments. At Prime Intellect, we utilize sandboxes extensively to generate RL rollouts for our training runs and have first-hand experience with their compute demands. We've been working on benchmarking real-world sandbox workloads with the new Vera CPU system.
Our experiences with sandboxes show that most require only 1–2 vCPUs and run in tandem with an inference loop. Workloads are predominantly single-threaded and bursty, fluctuating between heavy and idle periods, and they also have very strict startup latency requirements. We leverage VM snapshotting for fast boot times, which is sensitive to memory latency.
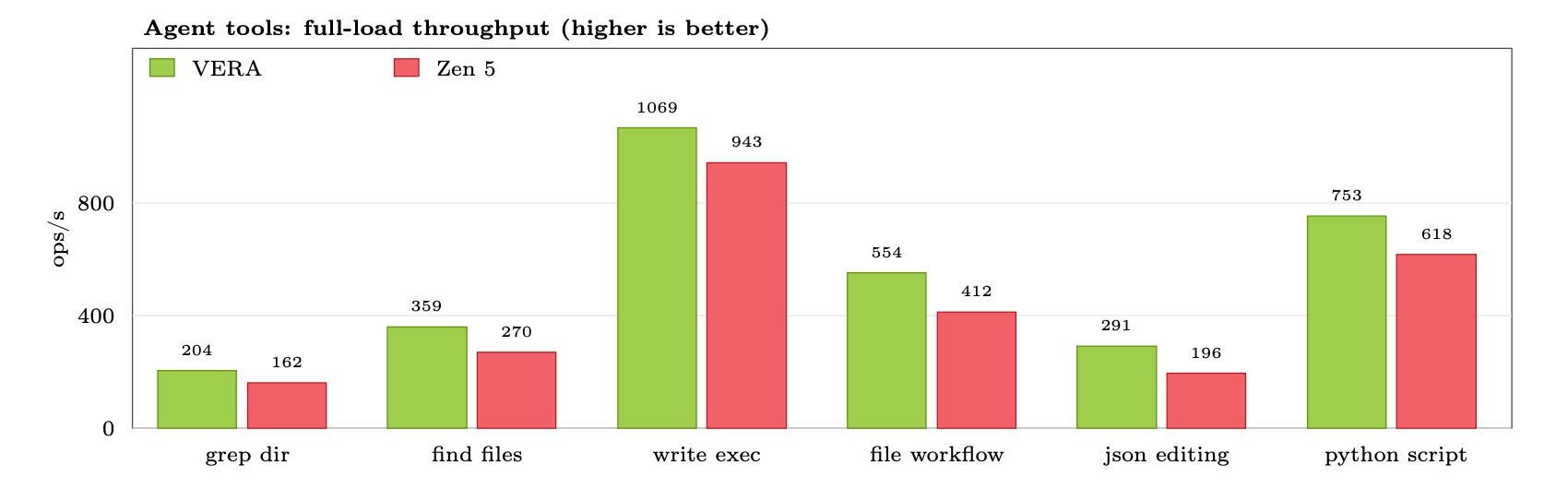
Our benchmarks on Vera indicate that the platform excels for our use cases. Each Vera socket offers 88 cores, with Spatial Multithreading enabling 176 total threads. We are able to stably run 176 VMs simultaneously on each socket. This level of sandbox density translates directly to operational cost savings, making Vera an economically advantageous solution. Beyond economics, the performance results are equally compelling. With SMT enabled, we recorded an average throughput increase of approximately 20% over SMT-disabled configurations. When comparing realistic RL sandbox workloads against AMD Zen 5, Vera with SMT delivers, on average, 30% greater throughput per CPU. For this comparison, the AMD Zen 5 baseline was run on AWS, where only physical cores are enabled.
For memory, we ran a dynamic load latency test designed to simulate the demands of a system running many sandboxes concurrently. The results demonstrate two key strengths: Vera makes full use of its memory bandwidth with relatively few streaming cores, and memory latency stays low and flat even as pressure on the memory channels increases. This experiment serves as a proxy for sandbox workloads, where some, but not all, sandboxes on the system are actively accessing memory at a given instant. Under this regime, Vera maintains high bandwidth and low memory latency, advantages that translate directly to real-world gains. When compared against AMD Zen 5, Vera makes full use of its memory bandwidth sooner, sustains significantly higher throughput, and keeps latency lower as memory pressure grows. Crucially, in a production sandbox system where between 10 and 60 sandboxes are realistically accessing memory concurrently, Vera dominates throughout the entire steady-state operating zone.
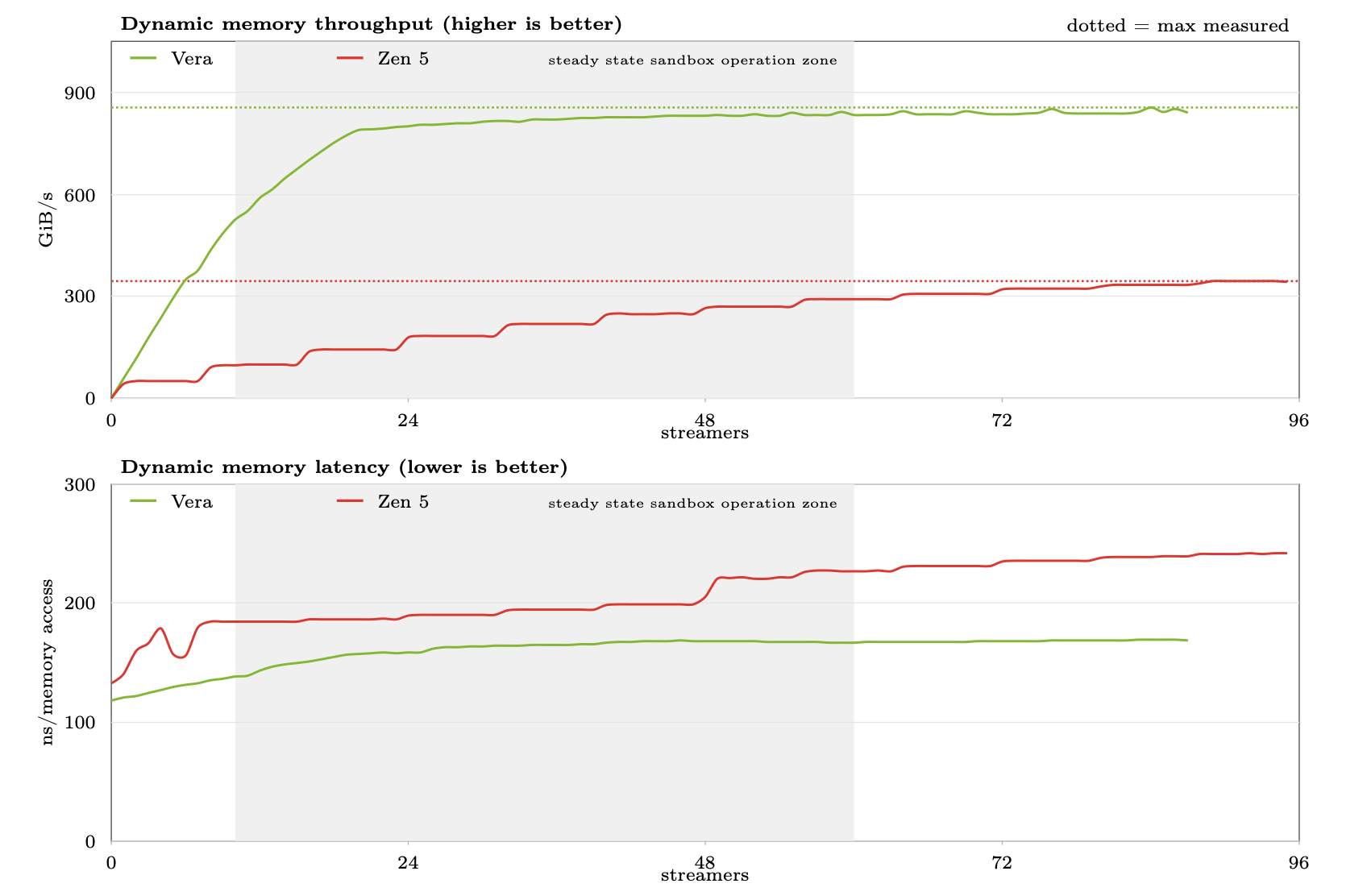
The memory benchmark is publicly available at dynamic-load-bench for independent reproducibility.
Prime Intellect plans to host our sandbox offering on Vera once it becomes publicly available, with GPU-enabled sandboxes also planned on top of Vera Rubin systems. The verifiers library, used to design and develop RL environments, fully supports sandbox-backed environments out of the box. Once enabled, RL researchers using our platform will benefit from the performance of sandboxes running on Vera with no changes to their environment definitions.
Advancing Reinforcement Learning with Prime Intellect and NVIDIA NeMo
Nemotron models are available for training through Lab, NVIDIA NeMo Gym environments integrate directly into verifiers, and the NVIDIA NeMo RL training stack also integrates with verifiers. We also collaborate on advancing open research, open datasets, and state-of-the-art open-source models. INTELLECT-3, for example, incorporated Nemotron datasets as part of a broader effort to push open-source models forward and expand access to frontier post-training.
This collaboration extends beyond infrastructure into models and research. We’re also working together on NVIDIA NemoClaw — an open source stack that simplifies running OpenClaw always-on assistants, more safely, with a single command. As part of the NVIDIA Agent Toolkit, it installs the NVIDIA OpenShell runtime—a secure environment for running autonomous agents, and open source models like NVIDIA Nemotron. As part of the NVIDIA Agent Toolkit, it installs the NVIDIA OpenShell runtime, a secure environment for running autonomous agents, and open-source models like NVIDIA Nemotron.
The NVIDIA stack has enabled us to build a more capable platform for post-training, agentic inference, and sandbox-backed reinforcement learning. As NVIDIA Vera Rubin becomes available, we look forward to deepening our collaboration with NVIDIA, continuing to integrate new tooling across our stack, and scaling agentic inference globally. Taken together, these steps move us closer to our long-term goal: enabling everyone to build self-improving agents.